RCNN
R-CNN是对滑窗的优化,很多什么都没有的区域进行卷积太浪费,先selective-search出可能有目标的区域

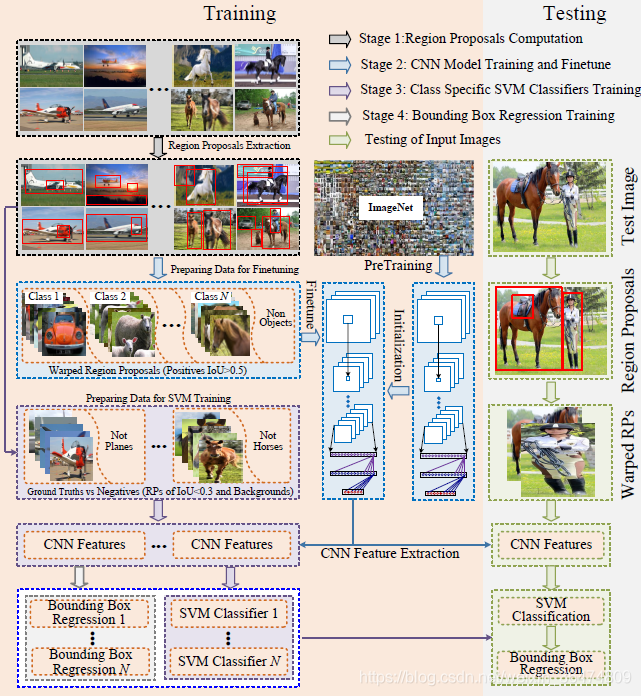
RCNN训练过程
- 先用ImageNet训练AlexNet
- 用标注的样本框对训练好的AlexNet进行fine-tune
- 用这个AlexNet提取出训练样本框的特征
- 用提取出的特征训练SVM分类器
- 首先通过选择性搜索,对待检测的图片进行搜索出~2000个候选窗口。
- 把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个proposal提取出一个特征向量,
- 也就是说利用CNN对每个proposal进行提取特征向量。
- 把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
RCNN测试过程
-
运用SelectiveSearch的方式生成备选框
-
将生成的备选框送入AlexNet进行判断,回归类和回归框
RCNN缺点
-
多阶段的复杂的训练过程
-
SVM与备选框的生成过程非常耗费运算和存储资源
-
测试过程缓慢,对每一个备选框都要进行一次AlexNet+SVM分类
SPP-Net
《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》
在此之前,所有的神经网络都是需要输入固定尺寸的图片,比如224224(ImageNet)、3232(LenNet)、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。
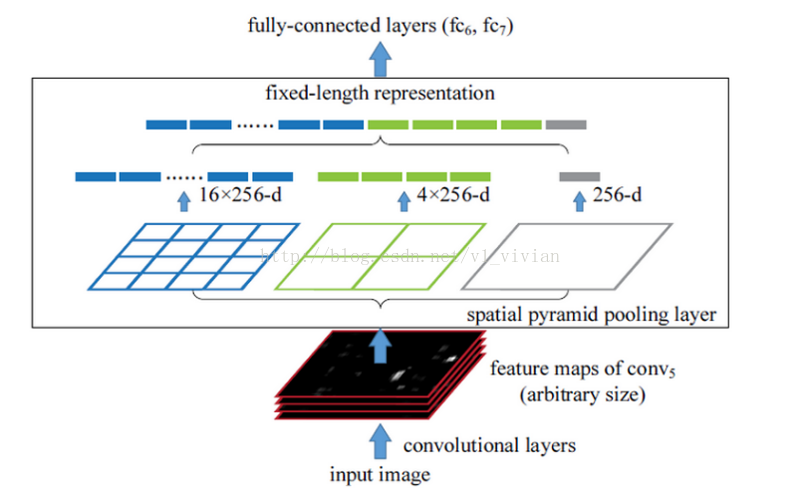
SPP-Net在卷积层后同时进行三个池化,分别是把图片分成16分,4份和1份,每一份不管是做平均池化还是最大池化,我们知道,输出只有(16+4+1=)25个特征值了,对接后面的fc层就是固定的了,也就是说不需要固定输入图片的大小了。
这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量)。
Fast R-CNN
用卷积算法实现滑窗,加快了时间,但在取得候选区域的选取上仍然很耗时间,于是有了何凯明的
Faster R-CNN
对候选区域,也用卷积来选取,而不是传统的颜色分割来取得色块
Selective Search

- step0:生成区域集R,具体参见论文《Efficient * Graph-Based Image Segmentation》
- step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
- 论文考虑了颜色、纹理、尺寸和空间交叠这4个参数。
- step2:找出相似度最高的两个区域,将其合并为新集,添加进R
- step3:从S中移除所有与step2中有关的子集
- step4:计算新集与所有子集的相似度
- step5:跳至step2,直至S为空
在OpenCV的contrib模块中实现了selective search算法。类定义为:
cv::ximgproc::segmentation::SelectiveSearchSegmentation