Interview
Core Foundation
由于 Core Foundation 使用手动引用计数,你需要遵循 Create Rule 的原则:
- 当函数名中包含
Create或Copy时,调用者拥有返回对象的所有权,负责在不再需要时使用CFRelease()释放对象。 - 当函数名中包含
Get,调用者不拥有返回对象的所有权,通常不需要释放。例如,使用CFStringCreateWithCString创建的字符串,在使用完毕后需要调用CFRelease进行释放。
理解 Toll-Free Bridging
它允许某些 Core Foundation 类型(如 CFStringRef)和Foundation 中的对应类型(如 NSString )在运行时可以被视为同一事物,从而在函数或方法参数中直接替换。在 ARC 环境下,为了在两种类型间安全转换并明确所有权归属,需要使用特定的桥接关键字:
-
__bridge:仅进行类型转换,不转移所有权。适用于对象生命周期由 ARC 管理的情况。(转成Foundation) *__bridge_retained(或CFBridgingRetain):将 Objective-C 对象转换为 Core Foundation 对象,同时将所有权转移给调用者,调用者需负责后续的 CFRelease。 __bridge_transfer(或CFBridgingRelease):将 Core Foundation 对象转换为 Objective-C 对象,并将所有权移交 ARC 管理
内存管理
ARC 背后的原理是依赖编译器的静态分析能力,通过在编译时找出合理的插入引用计数管理代码,从而彻底解放程序员。(其实就是交给runtime来管理)
- 当我们创建一个新对象的时候,它的引用计数为 1,
- 当有一个新的指针指向这个对象时,我们将其引用计数加 1,
- 当某个指针不再指向这个对象是,我们将其引用计数减 1,
- 当对象的引用计数变为 0 时,说明这个对象不再被任何指针指向了,这个时候我们就可以将对象销毁,回收内存。
在 Linux 文件系统中,我们用 ln 命令可以创建一个硬链接(相当于我们这里的 retain),当删除一个文件时(相当于我们这里的 release),系统调用会检查文件的 link count 值,如果大于 1,则不会回收文件所占用的磁盘区域。直到最后一次删除前,系统发现 link count 值为 1,则系统才会执行直正的删除操作,把文件所占用的磁盘区域标记成未用。
如果不传递引用,而是复制,则不会存在这些问题,但会带来大量的消耗。
对于一个 NSNumber 对象,如果存储 NSInteger 的普通变量,那么它所占用的内存是与 CPU 的位数有关,在 32 位 CPU 下占4个字节。而指针类型的大小通常也是与 CPU 位数相关,一个指针所占用的内存在32位 CPU 下为4个字节。但是迁移至64位系统中后,其占用空间达到了8字节,以此类推,所有在64位系统中占用空间会翻倍的对象,在迁移后会导致系统内存剧增,即时他们根本用不到这么多的空间。在2013年9月,苹果推出了iPhone 5s,该款机型首次采用64位架构的A7双核处理器。所以苹果对于一些小型数据(NSNumber、NSDate、NSString等),采用了 taggedPointer 这种方式管理内存。
TaggedPointer 是一种为内存高效节省空间的方法,Tagged Pointer是一个特别的指针,它分为两部分:
一部分直接保存数据 ; 另一部分作为特殊标记,表示这是一个特别的指针,不指向任何一个地址;
objc_objcet 对象中 isa 指针分为指针型 isa 与非指针型isa(NONPOINTER_ISA),运用的便是类似这种技术。下面详细解读一下NONPOINTER_ISA:
64位指针
在一个64位的指针内存中
- 第0位存储的是indexed标识符,它代表一个指针是否为NONPOINTER型,0代表不是,1代表是。
- 第1位 has_assoc,顾名思义,1代表其指向的实例变量含有关联对象,0则为否。
- 第2位为 has_cxx_dtor,表明该对象是否包含 C++相关的内容或者该对象是否使用 ARC 来管理内存,如果含有 C++ 相关内容或者使用了 ARC 来管理对象,这一块都表示为 YES,
- 第3-35位 shiftcls存储的就是这个指针的地址。
- 第42位为 weakly_referenced,表明该指针对象是否有弱引用的指针指向。
- 第43位为 deallocing,表明该对象是否正在被回收。
- 第44位为 has_sidetable_rc,顾名思义,该指针是否引用了 sidetable 散列表。第
- 45-63位 extra_rc 装的就是这个实例变量的引用计数,当对象被引用时,其引用计数+1,但少量的引用计数是不会直接存放在 sideTables 表中的,对象的引用计数会先存在 NONPOINTER_ISA 的指针中的45-63位,当其被存满后,才会相应存入 sideTables 散列表中。
散列表(SideTables)
SideTables 是一个全局的、在 Runtime 初始化时就被创建好的数据结构,它的核心作用是作为所有对象额外信息的“中央管理仓库”,并通过分离锁(Striped Map) 技术来高效、线程安全地管理成千上万个对象的引用计数和弱引用。而一个散列表中又包含众多 SideTable 结构体。每个 SideTable 中又包含了三个元素,spinlock_t 自旋锁,RefcountMap 引用计数表,weak_table_t 弱引用表。
它使用对象的内存地址当它的 key。管理引用计数和 weak 指针就靠它了。
就是内存地址是key,指向这个内存的“指针们”就是值,某内存地址引用为零时,反查出这些指针,将其置nil
Atomic
atomic 和 nonatomic 的区别在于,系统自动生成的 getter/setter 方法不一样。如果你自己写 getter/setter,那 atomic/nonatomic/retain/assign/copy 这些关键字只起提示作用,写不写都一样。
// @property(nonatomic, strong) UITextField *userName;
// 系统生成的代码如下:
- (UITextField *) userName {
return userName;
}
- (void) setUserName:(UITextField *)userName_ {
[userName_ retain];
[userName release];
userName = userName_;
}
// @property(retain) UITextField *userName; // 不写就是atomic
// 系统生成的代码如下:
// 可见加了锁
- (UITextField *) userName {
UITextField *retval = nil;
@synchronized(self) {
retval = [[userName retain] autorelease];
}
return retval;
}
- (void) setUserName:(UITextField *)userName_ {
@synchronized(self) {
[userName release];
userName = [userName_ retain];
}
}
管读写安全,但不管生命安全,比如几个线程来读写,atomic锁的机制会让他们变成串行操作,但是如果有release等消息发过来,还是会并行处理掉。
标记atomic的property生成的getter、setter内部使用了spinlock_t自旋锁保证了getter、setter的访问安全。
这里的spinlock_t并不是真正的自旋锁,iOS 10以后,底层换成了os_unfair_lock(互斥锁)。
因为反正不能保证线程安全,iOS应用几乎所有属性都可以设置为
nonatomic
浅拷贝与深拷贝
浅拷贝就是对象地址不变(引用数加1),但是指针多了一个(所以引数才会加1),深拷贝就是内容复制
- immutable对象的copy方法进行了浅拷贝
- immutable对象的mutableCopy方法进行了深拷贝
- mutable对象的copy方法进行了深拷贝
- mutable对象的mutableCopy方法进行了深拷贝。 总之, 没有必要创建新对象的, 就是浅拷贝, 事实上只有不可变对象拷贝到不可变对象, 才支持这种场景
从集合内的元素的角度而言, 对任何集合对象(可变和不可变集合)进行的 copy 与 mutableCopy 操作都可以称之为浅拷贝,即集合元素永远只能浅拷贝,深拷贝只能用指定的api实现比如copyItems:,copyWithZone: 或 initWithDictionary:copyItems:YES 等专用 API
- [immutableCollection copy] // 浅拷贝
- [immutableCollection mutableCopy] //浅拷贝,也可以称之为“单层深拷贝”。
- [mutableCollection copy] //浅拷贝,也可以称之为“单层深拷贝”。
- [mutableCollection mutableCopy] //浅拷贝,也可以称之为“单层深拷贝”。
所谓的单层深拷贝, 就是集合本身“深”拷贝了(新对象,新地址),但是集合内的元素“浅”拷贝了(引用数加1)。
[initWithArray: copyItems:]
- 如果为true,则是每一个元素都会
copyWithZone - 如果为false,那么每个元素只会被retain一次
retain就是浅拷贝,下一节刚好要说这个
分析
可变对象与不可变对象内部的实现不一样,单纯让指针指向同一个对象,会破坏可变或不可变的语义,所以不会这么设计,基于这一点你能够绝对判断:
mutalbe与immutalbe互转,只能用新对象来接,必然是“深拷贝”mutalbe的mutableCopy,强行定义和实现为“深拷贝”,因为它的语义就是新创造一个可变的对象。所以任意对象的mutalbeCopy在这个语义下就已经是深拷贝了,都不需要用前面的结论来推导。
@property (Private)
这一段看了几遍之后我加的内容,先看:
- OC的点语法,既能表示调方法,也能表示调属性,不像别的语言,不加括号,那一定是调属性。所以当你
self.name时,它不代表只能访问属性 - OC的状是,如果你啥也不做,用
property声明一个属性,编译器会自动帮你生成一个_name的实例变量,以及name的getter和setter方法 - 问题来了,生成的这个
getter方法,就是name, 恰好命中第1条,也就是说,此时的self.name == [self name]- 而
[self name]只是一个getter,它在里面取_name。
- 而
一个假说看破:
如果OC设计为,自动生成的
getter方法必须有get前缀,像JAVA的要约定那样,那么根本不需要弄一个叫_name的存储属性,仅仅为了避免语义冲突。然而,这是SamllTalk时期遗留下来的,它们的getter没有强制约束前缀。
即,如果只能self.getName或[self getName],那么存储属性完成可以直接就是name,而无需引入synthesize之类的一堆补丁。
多讲一点,看下面的C#代码:
public class Person {
public string Name { get; set; }
}
C#有个特殊之处,它的"属性“是一等公民,独立于变量和方法之外,也就是说,用点语法调属性,既不是在读变量,也不是在调方法,而就是在调属性。所以可以用person.Name来访问属性,而OC表面上一模一样,但本质上不同。(虽然其实也是person.get_Name()`,但这发生在编译期,而不是语法糖。
下面是历史笔记:
当我们用@property来声明属性变量时,编译器会自动为我们生成一个以下划线加属性名命名的实例变量(@synthesize copyyStr = _copyyStr),并且生成其对应的getter、setter方法。
当我们用self.copyyStr = originStr赋值时,会调用coppyStr的setter方法,而_copyyStr = originStr 赋值时给_copyyStr实例变量直接赋值,并不会调用copyyStr的setter方法,而在setter方法中有一个非常关键的语句:
_copyyStr = [copyyStr copy];
所以用点语法赋值其实是copy,而直接用赋值给下划线的话就看你代码是什么了。
@synthesize (Private)
你重写了属性的getter和setter,系统就不会生成对应的ivar(带下划线的实例变量),这时
- 要么,手动添加实例变量:NSString *_title;
- 要么,手动synthesize一下
- 如果你的getter和setter方法中用到了_title,那么编译器会自动合成
- 但用的不是_tilte而是别的,比如_titleStr,那么编译器就不会自动合成, 但不报错,运行时就崩溃了
如果 @synthesize (Private) 和 @dynamic (Private) 都没写,那么默认的就是@syntheszie var = _var;
copy
copy的属性就是为了自己持有,
-
要么这个对象可能会改变(比如mutable string, array等)
-
要么这个对象可能会消失(比如函数里定义了个block,存起来将来用,但是函数退出它就不在了)
-
对string进行copy,是浅拷贝(有新指针,没新对象)
-
对mutable string进行copy,是深拷贝(内容复制,新指标,新对象) -> 拷贝后变成了immutable string
而对block进行copy是MRC的遗留产物,在某个方法体内定义一个block并设置为一个对象的属性的时候,这个block是一个(方法里普通的分配到)栈上的local variable,所以这个方法退出后,这个block也就消失了。
而ARC时代会自动copy,苹果希望你仍然保留copy是在书面上明示一下,但是不写或者strong也没问题了。
不考虑ARC时代的自动copy,你属性声明一个block,必须得在一个函数体里实现对吧?可是函数一结束,你刚赋的那个block的内存地址就废了,等同于你赋了个寂寞。只有copy起来,才能保留这个实现
延伸一下,在方法内给实例的属性赋值(这个实例可能是self, 也可能来自方法入参,或是全局/单例等),这些值都是要保证方法结后目标对象的属性还持有这些值的:
- 值属性,直接复制
- 对象属性,传地址,引用数+1
- block,copy.
@dynamic (Private)
当一个属性声明为 dynamic 时 就是告诉编译器:开发者一定会添加 setter/getter 的实现,而编译时不用自动生成。
你没有提供setter/getter编译时也不会报错,但运行时你没有提供相应的方法就会导致程序崩溃
@synchronized (Private)
它是加锁,但又不是NSLock,它用着更方便,可读性更高。
- (void)push:(id)element
{
[_lock lock];
[_elements addObject:element];
[_lock unlock];
}
// synchronized版本:
- (void)increament:(id)element
{
@synchronized(self) {
[_elements addobject:element];
}
}
- 你可以给任何 Objective-C 对象上加个 @synchronized。那么我们也可以在上面的例子中用 (Private) @synchronized (Private)(_elements) 来替代 @synchronized (Private)(self),效果是相同的。
- @synchronized (Private) block 在被保护的代码上暗中添加了一个异常处理。为的是同步某对象时如若抛出异常,锁会被释放掉。
- @synchronized (Private) block 会变成
objc_sync_enter和objc_sync_exit的成对儿调用。(<objc/objc-sync.h>)
typedef struct SyncData {
id object;
recursive_mutex_t mutex;
struct SyncData* nextData;
int threadCount;
} SyncData;
typedef struct SyncList {
SyncData *data;
spinlock_t lock;
} SyncList;
// Use multiple parallel lists to decrease contention among unrelated objects.
#define COUNT 16
#define HASH(obj) ((((uintptr_t)(obj)) >> 5) & (COUNT - 1))
#define LOCK_FOR_OBJ(obj) sDataLists[HASH(obj)].lock
#define LIST_FOR_OBJ(obj) sDataLists[HASH(obj)].data
static SyncList sDataLists[COUNT];
- SyncList相当于一个链表,元素是SyncData(含有一个互斥锁),生成一个 data 时用 obj 的内存地址参与hash,添加到链表里
- 当你调用
objc_sync_enter(obj)时,它用 obj 内存地址的哈希值查找合适的 SyncData,然后将其上锁。 - 当你调用
objc_sync_exit(obj)时,它查找合适的 SyncData 并将其解锁。
swift中直接将synchronize删除了换成了上述
enter/exit对
objc_sync_enter 里面没有 retain 和 release。所以它要么没有保持传递给它的对象,要么或是在 ARC 下被编译。
-
synchronized 的 obj 为 nil 怎么办? 加锁操作无效。
-
synchronized 会对 obj 做什么操作吗? 会为obj生成递归自旋锁,并建立关联,生成 SyncData,存储在当前线程的缓存里或者全局哈希表里。
-
synchronized 和 pthread_mutex 有什么关系? SyncData里的递归互斥锁,使用 pthread_mutex 实现的。
-
synchronized 和 objc_sync 有什么关系? synchronized 底层调用了 objc_sync_enter() 和 objc_sync_exit()
可以用synchronized来实现不通过GCD的单例:
+ (instancetype)allocWithZone:(struct _NSZone *)zone {
static id instance = nil;
@synchronized (self) { // 互斥锁
if (instance == nil) {
instance = [super allocWithZone:zone];
}
}
return instance;
}
不用allocWithZone也没关系,比如sharedInstance,使用的时候知道是什么名称就行。
ARC与MRC
retain就是浅拷贝
retain本质上就是用一个变量存内存地址(对应到C语言),然后比C语言多做了一件事,就去跑去给这个内存地址的引用计数加1。- 因为多做了这一件事,所以就有一个对应的反向操作(减1),即
release。 - 以上就是MRC做的事,
ARC时代,有了一个strong,它可以理解为retain的语法糖(会自动在合适的位置帮你添加retain和release) - 所以
ARC不是GC(垃圾回收),是编译时的 retain/release 自动插入- 编译期:扫描代码,在合适位置插入 retain/release
- 运行期:和 MRC 完全一样,没有额外的运行时开销(除了优化)
字符串和tagged pointer
alloc、new会引用+1,因为语义上就是开辟一个内存空间,这即成事实了(其实就是从0到1)- 字符串用
stringWithFormat且长度大于9时,引用计数才+1,为什么(因为有tagged pointer的存在,变量指针直接存值了)
长度大于9是表象,实际是再长的字符串就不能用tagged pointer来承载了。
tagged pointer
首先,理解指针:
NSString *str;
这行代码做了两件事:
- 在栈上分配 8 字节的空间(64位系统)
- 把这个空间命名为 str
这个 8 字节的空间里,将来要存一个地址(其他内存区域的编号)。
NSNumber、NSString、NSDate等小对象,用tagged pointer(后面简称TP)来存储,内存地址的一部分用来存储数据,一部分用来存储类型信息- 这个8个字节的空间,如果是局部变量,它在栈上;如果是实例变量,跟随宿主一起在堆上(跟普通int一样)
- 引用计数的本质是“一块内存空间(所代表的对象)有多少个指针在指向它“
- 既然
TP没有指向任何内存地址- 对
TP进行的retain和release只是语法上会通过,底层都忽略掉了,因为从语义上来看,不需要对不存在的东西进行引用计数
- 对
stringWith系列方法没走alloc,当系统发现足够短的时候,就用TP来优化了- 它能表现得像一个
NSString对象,完全是runtime的消息转发机制,当你对NSTaggedPointerString发送字符串相关方法是,runtime会帮你转发到NSString的方法上。记住它只是一个伪装成对象的指针(也根本没有内容计数)
这段代码有什么问题:
[NSString stringWithFormat:@"123456789"];
- 它不是野指针,因为只有指针指向的地址已经被释放了。它根本没有指向任何地址。(TP)
- 它没有内存泄露,只有对象还存在,已经没有任何指针指向它才叫泄露。TP没有申请内存,不存在这个问题
[[NSString alloc] initWithFormat:@"123"]这样就泄露了,分配了内存,但没有任何指针指向它
而这段代码只产生了一个指针,会随着方法结束自动释放。
OC的对象变量
OC的对象变量可以理解为就是指向地址的地址,或指向地址的指针. 这块地址是你alloc出来的,copy的时候创建的,还是直接指向的,身份都是一样的,只影响指向它的计数。alloc的人没有任何特殊。
什么是内存地址
物理层面:
- 内存芯片内部有 10 亿个存储单元(电容+晶体管)
- 每个单元可以存 1 位(0 或 1)
逻辑层面:
- 操作系统/CPU 把 8 个连续的单元编组为 1 个字节
- 然后给每个字节分配一个编号:0x0000, 0x0001, 0x0002...
- 这个编号就是内存地址 <- 内存地址就是个映射表(的索引)!
同一条内存,哪怕是两次开机,产生的地址也是不一样的:
- 8位一组的方式不会变,它是硬件决定的(比如每8个位线一组)
- 但是地址的编号会变,因为操作系统每次加载会重新分配逻辑地址
- 同一个物理单元对应哪个逻辑地址也就变了
内存是在引导期被初始化的,然后才是加载操作系统,操作系统看到的内存已经是字节了(看不到它后面8位一组的物理电容)
Runtime
OC 是一门动态语言,函数调用变成了消息发送,在编译期不能知道要调用哪个函数。所以 Runtime 无非就是去解决如何在运行时期找到调用方法这样的问题。 instance -> class -> method -> SEL -> IMP -> 实现函数
上面从method起的三节其实是一个东西:
- SEL是key,查找的依据
- IMP是值,查找的目的,它是一个函数指针
- Method 是 key + value + metadata 的容器
typedef struct objc_method *Method;
struct objc_method {
SEL method_name; // 方法名(如 "doSomething")
char *method_types; // 类型编码(如 "v@:")
IMP method_imp; // 函数指针
};
- 当一个对象 sender 调用代码[receiver message];的时候,实际上是调用了runtime的objc_msgSend函数,
- 所以OC的方法调用并不像C函数一样能按照地址直接取用,而是经过了一系列的过程。
- 这样的机制使得 runtime 可以在接收到消息后对消息进行特殊处理,这才使OC的一些特性譬如:
- 给 nil 发送消息不崩溃,
- 给类动态添加方法和消息转发等成为可能。
- 也正因为每一次调用方法的时候实际上是调用了一些 runtime 的消息处理函数,OC的方法调用相对于C来说会相对较慢,
- 但 OC 也通过引入 cache 机制来很大程度上的克服了这个缺点。
isa指向的是类对象,在里面可以找到方法,属性
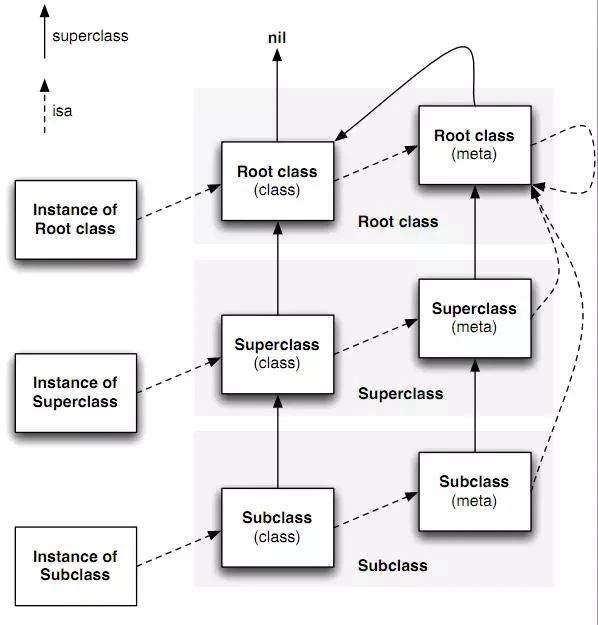
- instance
isaclass - class
isameta class Root Class就是NSObject,没有超类- 任何meta class
isaRoot meta class - root meta class 的父类是root class
- 要记得root class
isaroot meta class,这里反向指回来了
- 要记得root class
类中的 super_class 指针可以追溯整个继承链。向一个对象发送消息时,Runtime 会根据实例对象的 isa 指针找到其所属的类,并自底向上直至根类(NSObject)中 去寻找 SEL 所对应的方法,找到后就运行整个方法。
metaClass是元类,也有 isa 指针、super_class 指针。其中保存了类方法列表。
objc_msgSend 函数的调用流程:
- 检测 SEL 是否应该被忽略
- 检测发送的 target 是否为 nil ,如果是则忽略该消息
- 当调用实例方法时,通过 isa 指针找到实例对应的 class 并且在其中的缓存方法列表以及方法列表中进行查询,如果找不到则根据 super_class 指针在父类中查询,直至根类(NSObject 或 NSProxy).
- 当调用类方法时,通过 isa 指针找到实例对应的 metaclass 并且在其中的缓存方法列表以及方法列表中进行查询,如果找不到则根据 super_class 指针在父类中查询,直至根类(NSObject 或 NSProxy).
- 如果还没找到则进入消息动态解析过程(resolve / forward)。
+ (BOOL)resolveClassMethod:(SEL)sel;
+ (BOOL)resolveInstanceMethod:(SEL)sel;
//后两个方法需要转发到其他的类处理
- (id)forwardingTargetForSelector:(SEL)aSelector; // 这个返回值是id,可见是期望你返一个能处理这个SEL的对象
- (void)forwardInvocation:(NSInvocation *)anInvocation;
// 调用一个不存在的方法:
[target performSelector:@selector(resolveAdd:) withObject:@"test"];
// 在target内部handle住
void runAddMethod(id self, SEL _cmd, NSString *string){
NSLog(@"add C IMP ", string);
}
// 第一次补救
+ (BOOL)resolveInstanceMethod:(SEL)sel{
// 原生方法返回No,
// 这里加入自己的处理,其实就是把方法“添加”进去
if ([NSStringFromSelector(sel) isEqualToString:@"resolveAdd:"]) {
class_addMethod(self, sel, (IMP)runAddMethod, "v@:*");
}
return YES;
}
// 第二次补救
- (id)forwardingTargetForSelector:(SEL)aSelector {
NSString * methodName = NSStringFromSelector(aSelector);
if ([methodName isEqualToString:@"sendMessage:"]) {
return [Man new]; // 即返一个能处理的对象
}
return [super forwardingTargetForSelector:aSelector];
}
// 第三次补救
// 先用下面的方法获得函数签名(参数,返回值)
// 如果返回nil, 则发doesNotRecognizeSelector消息
- (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector {
NSString * methodName = NSStringFromSelector(aSelector);
if ([methodName isEqualToString:@"sendMessage:"]) {
return [NSMethodSignature signatureWithObjCTypes:"v@:@"];
}
return [super methodSignatureForSelector:aSelector];
}
// 把获取到的方法签名包装成NSInvocation传入
- (void)forwardInvocation:(NSInvocation *)anInvocation {
SEL sel = [anInvocation selector];
Man * tempObj = [Man new];
if ([tempObj respondsToSelector:sel]) {
[anInvocation invokeWithTarget:tempObj];
}else {
[super forwardInvocation:anInvocation];
}
}
resolveInstanceMethod方法里可以添加一些通用处理逻辑,比如记录日志等,但是真实业代码只能交由addMethod来执行,因为这个方法返回后,会立即进行一次查询(不依赖于你返的是YES还是NO) 返回值的意义在于影响respondsToSelector,及后续步骤是否需要执行,或者是否需要重复执行resolveInstanceMethod,所以乱返,只有在你真正添加了method后才返回YES。
v@:意思就是这是一个void类型的方法,没有参数传入。i@:就是说这是一个int类型的方法,没有参数传入。i@:@就是说这是一个int类型的方法,有一个参数传入。
上述方法是用v@:等语法生造一个签名,这种方法不安全,如果调用对象方法签名变了就会出错,可以用目标对象来提供这个方法签名:
// 1. 为未知的选择子返回一个有效的方法签名
- (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector {
// 检查当前选择子是否为需要转发的read方法
if (aSelector == @selector(read)) {
// 从能响应此选择子的Reader实例获取方法签名
// 前提是在本.m文件中把这个处理类(_reader实例化好)
NSMethodSignature *signature = [_reader methodSignatureForSelector:aSelector];
if (signature) {
return signature;
}
}
// 对于其他未知选择子,调用父类的实现
return [super methodSignatureForSelector:aSelector];
}
// 2. 将调用转发给目标对象
- (void)forwardInvocation:(NSInvocation *)anInvocation {
// 判断需要转发的选择子
if (anInvocation.selector == @selector(read)) {
NSLog(@"Book 无法响应 read 方法,将消息转发给 Reader...");
// 将调用目标设置为_reader,从而调用Reader的read方法
[anInvocation invokeWithTarget:_reader];
} else {
// 对于其他选择子,调用父类的实现
[super forwardInvocation:anInvocation];
}
}
总结下, Objective-C Runtime在调用一个对象上未实现的方法(unrecognized selector) 时,会依次尝试 三个补救阶段:
- 动态方法解析(Dynamic Method Resolution),给你一次机会,在运行时动态添加这个缺失方法的实现(IMP) 到类中
- 快速消息转发(Fast Forwarding),允许你返回另一个能响应该 selector 的对象
- 不能修改消息参数
- 完整消息转发(Full Message Forwarding)
-methodSignatureForSelector:→ 提供方法签名-forwardInvocation:→ 处理完整的 NSInvocation 对象- 可以完全控制消息的转发逻辑:修改参数、记录日志、网络调用、动态计算等。
- 开销最大(要创建 NSMethodSignature 和 NSInvocation)。
- 最灵活,是 AOP、RPC、Mock 框架的基础。
如果你没有在类里实现 forwardInvocation:,当消息发送失败时,Runtime 最终会调用 NSObject 的 doesNotRecognizeSelector:,这个方法就是抛出异常导致 Crash 的地方。
[obj someMethod]
↓
1. 消息发送(objc_msgSend)
- 查缓存 → 查方法列表 → 找到 IMP → 调用 ✅
↓ 未找到
2. 动态方法解析(resolveInstanceMethod: / resolveClassMethod:)
- 你可以在这里用 class_addMethod 添加方法实现
- 添加后,Runtime 重新查找并调用 ✅
↓ 你没有实现这个方法,或者实现了但没有添加方法
3. 快速转发(forwardingTargetForSelector:)
- 你可以在这里返回另一个对象,让那个对象处理
- Runtime 会直接向那个对象发送消息 ✅
↓ 你返回 nil 或没有实现这个方法
4. 完整转发(forwardInvocation:)
- 你可以在这里做任何处理:转发给其他对象、归档、记录日志等
- 需要配合 methodSignatureForSelector: 返回方法签名
↓ 你没有实现 forwardInvocation:(或者调用了 super)
5. doesNotRecognizeSelector:
- NSObject 的 forwardInvocation: 默认实现会调用这个方法
- 默认实现抛出 NSInvalidArgumentException 异常 ❌
forwardInvocation: 的本质:
- (void)forwardInvocation:(NSInvocation *)anInvocation {
// 1. 找一个能处理这个调用的对象
id target = [self findTargetThatCanHandle:[anInvocation selector]];
// 2. 把调用交给它(就这么简单)
[anInvocation invokeWithTarget:target];
}
全局防崩溃
上面说的全是针对特定类的防崩溃(未知selector),意思是你要在特定的类里写那些代码,如果想全局的话,有个进阶方案: 全局 Hook + 转发 = 通用防崩溃
- 第一步:Hook(挂钩)
我们不能修改
NSArray的源码,但我们可以利用Method Swizzling,替换掉NSObject的forwardInvocation:方法。因为几乎所有类都继承自NSObject。 - 第二步:转发(转发到统一处理中心)
在自定义的
xxx_forwardInvocation:方法中,你可以写通用的逻辑。因为现在任何对象只要找不到方法,都会先走这个被替换了的forwardInvocation:。* 判断: 判断当前对象(self)是不是 NSArray?是不是 NSString? * 处理: 如果是数组且方法是 `objectAtIndex:`,则在这里处理异常,返回 nil 或打印日志,阻止 `Crash`。
伪代码:
// 通过 Swizzling,让所有对象的 forwardInvocation 都指向了这个方法
- (void)xxx_forwardInvocation:(NSInvocation *)invocation {
SEL selector = [invocation selector];
// 针对特定的类(如 __NSArrayI)做特定的防护
if ([self isKindOfClass:NSClassFromString(@"__NSArrayI")]) {
if (selector == @selector(objectAtIndex:)) {
// 处理数组越界逻辑,直接返回,不调用 doesNotRecognizeSelector:
return;
}
}
// 如果不是我们处理的范围,或者处理不了,还是要走原来的流程,否则会破坏系统逻辑
// 这里调xxx_才是原来的方法,注意
[self xxx_forwardInvocation:invocation];
}
objc/runtime.h定义的类,方法,属性,协议等:
typedef struct objc_method *Method;
typedef struct objc_ivar *Ivar;
typedef struct objc_category *Category;
typedef struct objc_property *objc_property_t;
struct objc_class {
Class isa OBJC_ISA_AVAILABILITY;
#if !__OBJC2__
Class super_class OBJC2_UNAVAILABLE;
const char *name OBJC2_UNAVAILABLE;
long version OBJC2_UNAVAILABLE;
long info OBJC2_UNAVAILABLE;
long instance_size OBJC2_UNAVAILABLE;
struct objc_ivar_list *ivars OBJC2_UNAVAILABLE; // 成员变量地址列表
struct objc_method_list **methodLists OBJC2_UNAVAILABLE; // 方法地址列表
struct objc_cache *cache OBJC2_UNAVAILABLE; // 缓存最近使用的方法地址,以避免多次在方法地址列表中查询,提升效率
struct objc_protocol_list *protocols OBJC2_UNAVAILABLE; // 遵循的协议列表
#endif
} OBJC2_UNAVAILABLE;
/* Use `Class` instead of `struct objc_class *` */
获取这些列表:
unsigned int count;
//获取属性列表
objc_property_t *propertyList = class_copyPropertyList([self class], &count);
for (unsigned int i=0; i<count; i++) {
const char *propertyName = property_getName(propertyList[i]);
NSLog(@"property---->%@", [NSString stringWithUTF8String:propertyName]);
}
//获取方法列表
Method *methodList = class_copyMethodList([self class], &count);
for (unsigned int i; i<count; i++) {
Method method = methodList[i];
NSLog(@"method---->%@", NSStringFromSelector(method_getName(method)));
}
//获取成员变量列表
Ivar *ivarList = class_copyIvarList([self class], &count);
for (unsigned int i; i<count; i++) {
Ivar myIvar = ivarList[i];
const char *ivarName = ivar_getName(myIvar);
NSLog(@"Ivar---->%@", [NSString stringWithUTF8String:ivarName]);
}
//获取协议列表
__unsafe_unretained Protocol **protocolList = class_copyProtocolList([self class], &count);
for (unsigned int i; i<count; i++) {
Protocol *myProtocal = protocolList[i];
const char *protocolName = protocol_getName(myProtocal);
NSLog(@"protocol---->%@", [NSString stringWithUTF8String:protocolName]);
}
class_rw_t也存了类的方法属性和协议,什么鬼?
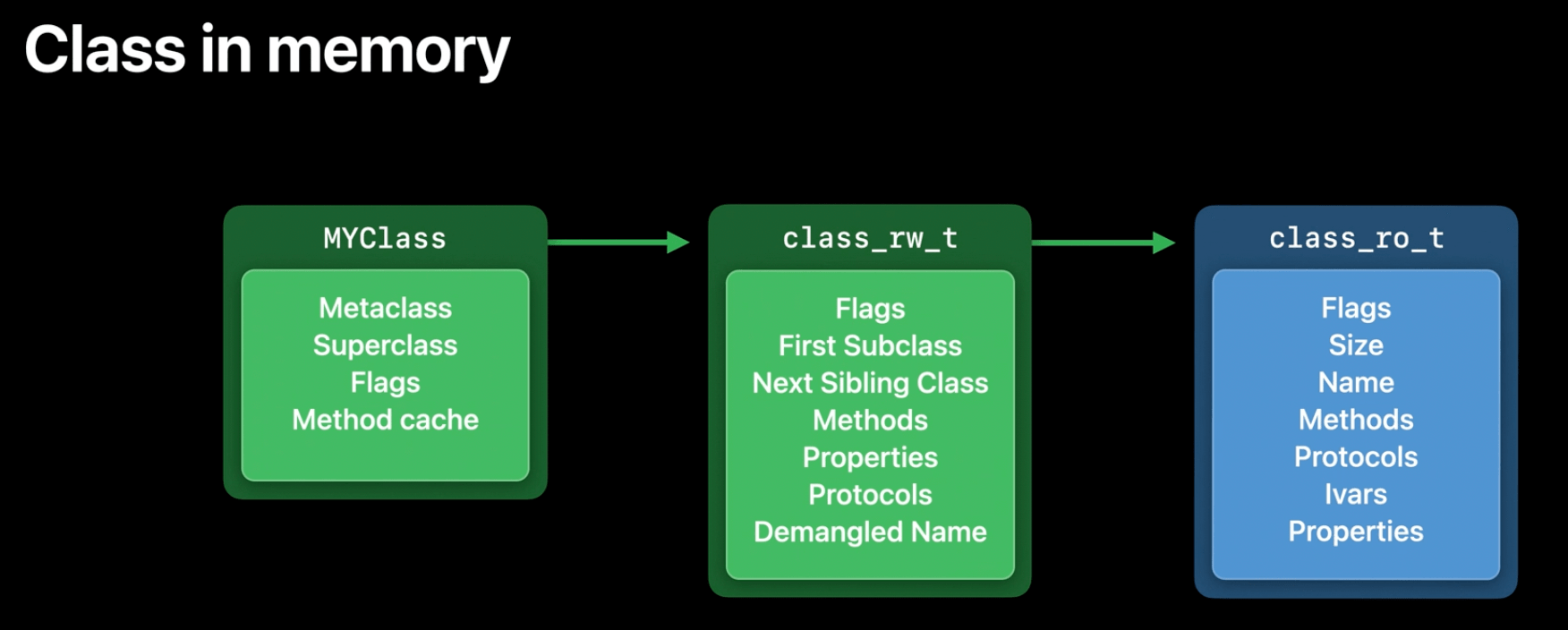 加载到内存中的时候(即运行时了)才有
加载到内存中的时候(即运行时了)才有class_rw_t:
When a class first gets used, the runtime allocates additional storage for it. This runtime allocated storage is the class_rw_t (read/write data).
In this data structure, we store new information only generated at runtime.(只存运行时添加的信息)
来源:WWDC
// 可读可写
struct class_rw_t {
// Be warned that Symbolication knows the layout of this structure.
uint32_t flags;
uint32_t version;
const class_ro_t *ro; // 指向只读的结构体,存放类初始信息
/*
这三个都是二位数组,是可读可写的,包含了类的初始内容、分类的内容。
methods中,存储 method_list_t ----> method_t
二维数组,method_list_t --> method_t
这三个二位数组中的数据有一部分是从class_ro_t中合并过来的。
*/
method_array_t methods; // 方法列表(类对象存放对象方法,元类对象存放类方法)
property_array_t properties; // 属性列表
protocol_array_t protocols; //协议列表
Class firstSubclass;
Class nextSiblingClass;
//...
}
而class_ro_t储存了当前类在编译期就已经确定的属性方法及协议(所以存在硬盘上):
struct class_ro_t {
uint32_t flags;
uint32_t instanceStart;
uint32_t instanceSize;
uint32_t reserved;
const uint8_t * ivarLayout;
const char * name;
method_list_t * baseMethodList;
protocol_list_t * baseProtocols;
const ivar_list_t * ivars;
const uint8_t * weakIvarLayout;
property_list_t *baseProperties;
};
runtime一些应用
在实际开发中如何利用 Runtime 的动态性来解决难题或实现黑魔法。
- 关联对象
利用
objc_setAssociatedObject和objc_getAssociatedObject为任何类(特别是系统类或三方类)动态添加属性。 - 方法交换(Method Swizzling),在不侵入业务代码的前提下,实现全局的功能修改或日志记录。但需要注意,通常只在
+load方法中执行,并确保线程安全。- 场景 A:无侵入埋点。 在不改动原有
ViewController代码的情况下,统计所有页面被浏览的次数。在+load方法中,交换 UIViewController 的viewWillAppear:和自定义的xxx_viewWillAppear:方法。在自定义方法中插入埋点代码,再调用原来的方法。 - 场景 B:数组越界防 Crash。 系统原始的 NSArray 的 objectAtIndex: 在越界时会崩溃。可以将其与自定义的 safeObjectAtIndex: 方法交换,在自定义方法中做安全校验。
- 场景 A:无侵入埋点。 在不改动原有
- 动态消息处理与转发
- 上面说的调到不存在的方法时的三次补救。
@dynamic的实现,在 resolveInstanceMethod: 中,利用 class_addMethod 动态地为属性的 Setter/Getter 添加实现(例如,实现 CoreData 或 JSON 转 Model 的动态赋值)。
isKindOfClass 与 isMemberOfClass
- 子类一定是父类的kind
- 但不是父类的member
所以:
- [man isKindofClass:[Person class]] // YES
- [man isMemberClass:[Person class]] // No
子类可以自动继承父类的属性,并不自从父类继承成员变量,需要synthesize一下
自旋锁和互斥锁
互斥锁在加锁失败后会进入睡眠状态等待,然后被唤醒,都有开销,而自旋锁则一直忙等待,但不会有上下文切换也不会有睡眠唤醒等等开销,如果确定等待的时间很短,应该用自旋锁。
优化
离屏渲染
离屏渲染就是在当前屏幕缓冲区以外,新开辟一个缓冲区进行操作。
离屏渲染发生在 GPU层面上,会创建新的渲染缓冲区,会触发 OpenGL的多通道渲染管线,图形上下文的切换会造成额外的开销,增加 GPU工作量。如果 CPU GPU累计耗时 16.67毫秒还没有完成,就会造成卡顿掉帧。
- 光栅化,layer.shouldRasterize = YES
- 遮罩,layer.mask
- 圆角,同时设置 layer.masksToBounds = YES、layer.cornerRadius大于 0
- 考虑通过 CoreGraphics绘制裁剪圆角,或者叫美工提供圆角图片
- 阴影,layer.shadowXXX,如果设置了layer.shadowPath就不会产生离屏渲染
如果这样的操作达到一定数量,会触发缓冲区的频繁合并和上下文的频繁切换,性能的代价会宏观地表现在用户体验上——掉帧
检测离屏渲染 1、模拟器 debug-选中 color Offscreen-Renderd离屏渲染的图层高亮成黄可能存在性能问题 2、真机 Instrument-选中 Core Animation-勾选 Color Offscreen-Rendered Yellow
图层混合
如果屏幕的一块区域上有多个图层(layer),每个图层都会有一定的透明度,那么最后这块区域的显示效果就是这些图层共同作用的结果,这种结果需要cpu对每个图层的颜色进行计算,需要消耗更多的cpu资源。如果我们把最上层的layer设定为不透明,那么cpu就不需要计算底层的layer的色值,这样就可以节约cpu的计算量,节约资源。
检测图层混合 1、模拟器 debug选中 color blended layers红色区域表示图层发生了混合 2、Instrument 选中 Core Animation勾选 Color Blended Layers
网络
GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包: 对于 GET 方式的请求,浏览器会把 Header 和实体主体一并发送出去,服务器响应 200(返回数据); 而对于 POST,浏览器先发送 Header,服务器响应 100 Continue,浏览器再发送实体主体,服务器响应 200 OK (返回数据)。
HTTP 持久连接怎么判断一个请求是否结束的?
-
Content-length:根据所接收字节数是否达到 Content-length 值
-
chunked(分块传输):Transfer-Encoding。当选择分块传输时,响应头中可以不包含
Content-Length,服务器会先回复一个不带数据的报文(只有响应行和响应头和\r\n),然后开始传输若干个数据块。当传输完若干个数据块后,需要再传输一个空的数据块,当客户端收到空的数据块时,则客户端知道数据接收完毕。
TCP
TCP是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的“连接”,其实是客户端和服务器的内存里保存的一份关于对方的信息,如ip地址、端口号等。
- TCP连接:三次握手
- TCP中断:四次挥手(服务器先确认,再断连,两次)
- 此时一个方向的连接关闭。但是另一个方向仍然可以继续传输数据,等到发送完了所有的数据后,会发送一个FIN段来关闭此方向上的连接。
- 当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方是否现在关闭发送数据通道,需要上层应用来决定,因此,己方ACK和FIN一般都会分开发送。
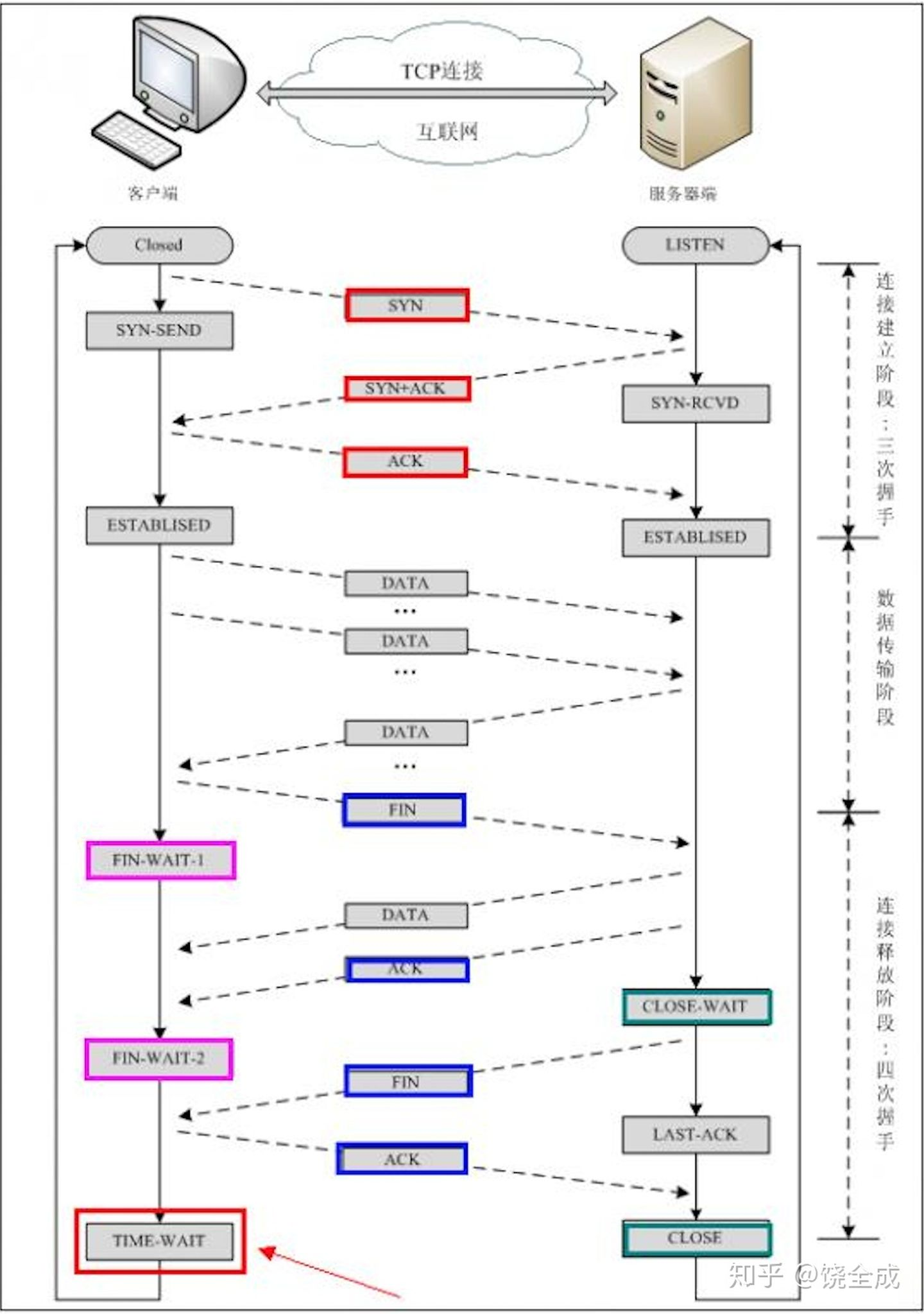
即TCP连接,都是为了达到一个ESTABLISHED状态,客户端一次发,一次收,即达到,服务端在第二步发,第三次收,也达到了这个状态,共三次。
而断开连接,上面说了,FIN只表示不再发了(等待状态1),所以另一方得到FIN后,先ACK回馈一次,再慢慢把数据发回(等待状态2),才也发个FIN表示自己也不发了,得到另一端的ACK回馈后,CLOSE,而另一端则到了(等待状态3)
网络层服务(IP 服务)是不可靠的。IP 不保证数据报的交付,不保证数据报的按序交付,也不保证数据报中数据的完整性。
TCP 则是在 IP 服务上创建了一种可靠数据传输服务
TCP 的可靠数据传输服务确保一个进程从其接收缓存中读出的数据流是无损坏、无间隔、无冗余、按序的
数据流。即该字节流与连接的另一端发出的字节流是完全相同的。
SSL
五次握手:
- 第一步,爱丽丝给出协议版本号、一个客户端生成的随机数(Client random),以及客户端支持的加密方法。
- 第二步,鲍勃确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数(Server random)。
- 第三步,爱丽丝确认数字证书有效,然后生成一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给鲍勃。
- 第四步,鲍勃使用自己的私钥,获取爱丽丝发来的随机数(即Premaster secret)。
- 第五步,爱丽丝和鲍勃根据约定的加密方法,使用前面的三个随机数,生成"对话密钥"(session key),用来加密接下来的整个对话过程。
前两次明文交换随机数,第三次生成非对称随机数,然后用协商的加密方法,以这三个随机数为种子生成接下来对称加密的密钥,也就是说前两个随机数其实不重要,只要第三个随机数拦截不了的话。
cookie
设置 Cookie 的 secure 属性为 true。浏览器只会在 HTTPS 和 SSL 等安全协议中传输此类 Cookie。
secure 属性并不能对 Cookie 内容加密,因而不能保证绝对的安全性。
如果在 cookie 中设置了 HttpOnly 属性,那么通过 js 脚本将无法读取到 cookie 信息,这样能有效的防止 XSS(跨站脚本攻击)攻击
多线程
主要有三种:NSThread、NSoperationQueue、GCD
GCD 是面向底层的 C 语言的 API , NSOpertaionQueue 用 GCD 构建封装的,是 GCD 的高级抽象。
1、 GCD 执行效率更高,而且由于队列中执行的是由 block 构成的任务,这是一个轻量级的数据结构,写起来更方便
2、 GCD 只支持 FIFO 的队列,而 NSOperationQueue 可以通过设置最大并发数,设置优先级,添加依赖关系等调整执行顺序
3、 NSOperationQueue 甚至可以跨队列设置依赖关系,但是 GCD 只能通过设置串行队列,或者在队列内添加 barrier(dispatch_barrier_async) 任务,才能控制执行顺序,较为复杂
4、 NSOperationQueue 因为面向对象,所以支持 KVO ,可以监测 operation 是否正在执行( isExecuted )、是否结束( isFinished )、是否取消( isCanceld )
实际项目开发中,很多时候只是会用到异步操作,不会有特别复杂的线程关系管理,所以苹果推崇的且优化完善、运行快速的 GCD 是首选
如果考虑异步操作之间的事务性,顺序行,依赖关系,比如多线程并发下载,GCD需要自己写更多的代码来实现,而 NSOperationQueue 已经内建了这些支持
不论是 GCD 还是 NSOperationQueue ,我们接触的都是任务和队列,都没有直接接触到线程,事实上线程管理也的确不需要我们操心,系统对于线程的创建,调度管理和释放都做得很好。而 NSThread 需要我们自己去管理线程的生命周期,还要考虑线程同步、加锁问题,造成一些性能上的开销
串行对列和并发队列
- get_main_queue就是一个特殊的串行队列,这个队列里的任务会放到主线程执行
- get_blobal_queue是默认提供的全局并发队列,构造的时候要传入一个优先级
dispatch_apply可以并发遍历数组,并且会等待所有操作完成,整个遍历表现得像“同步”的
之所以单例用gcd实现,是因为单例会碰到多线程的问题。
KVO
KVO和Runtime
KVO是依赖于Runtime来实现的,当我们设定了一个观察对象的时候,一个新的类会被动态的创建出来(NSKVONotifying_KVOObserved),这个类继承了被观察类的属性,并重写了被观察属性的setter方法。重写时添加了相应的通知,最后把isa指针(isa指针告诉Runtime系统的这个对象的类是什么)指向这个新建的类。
Apple 君为了隐藏 KVO 的实现细节,在动态生成的子类中重写了class方法,使其返回原有类的信息(当然通过object_getClass获取的isa指针信息是无法隐藏的)。
如果监听一个类的某个keypath,它的超类刚好也在监听,就会造成问题,可以用context来个性化,比如Person类和Student类都监听name属性:
static void * PersonNameContext = &PersonNameContext;
static void * StudentNameContext = &StudentNameContext;
这个时候在监听方法里就不是用keypath字符串去比较了,而是判断context是谁
对象属性的监听,那是因为属性值的变化由系统控制的,开发者只需要告诉系统监听什么属性便可以了,但是在实际的开发中我们有可能属性的值的变化并不需要受系统的支配。实际上除了系统自动监听属性值的变化外,还有一种方式便是可以由开发者支配属性的值变化后是否发送通知。只需要修改类方法 automaticallyNotifiesObserversForKey:的返回值,如果返回 YES 就是自动,返回 NO 就是手动。
如果设no,那么需要手动触发:
- (void)setName:(NSString *)name{
[self willChangeValueForKey:@"name"];
_name = name;
[self didChangeValueForKey:@"name"];
}
对于容器类还要更改索引,
[self willChange:NSKeyValueChangeRemoval valuesAtIndexes:[NSIndexSet indexSetWithIndex:index] forKey:@"mArray"];
以及多个属性之间的依赖等知识...
触摸事件链
扩大点击区域
1, 对于按钮
- (BOOL)pointInside:(CGPoint)point withEvent:(UIEvent *)event
{
return CGRectContainsPoint(self.bounds, point);
}
重写这个函数去更改bounds,让point能出现在bouns中,就能返true
这是子类化, 在子内里判断该point是否在bounds内.
2, runtime关联对象来改变范围,- (UIView) hitTest:(CGPoint) point withEvent:(UIEvent) event里用新设定的 Rect 来当着点击范围。
其实就是把要扩大的区域用associate object存起来
这是在容器View里用的, 即遍历(或指定)subview, 用方法1(原生的或被覆盖的)来判断是否在点击区域内
hittest和pointinside核心都是CGRectContainsPoint(rect, point)即触摸的点在不在指定的rect内
其实方法1和2是一起用的,在事件和响应链中:
- 用方法2(hittest)来确认离rootview最近的view,一旦找到,就不找了
- 再遍历该view的subview,从离rootview最远的subview开始遍历,如果没有改变索引,一般就是最后添加的subview开始,用方法1(pointinside)来确认点中的是哪个控件,找到就退出,不再往上找
hitTest
hitTest大致逻辑:
- (UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event {
//系统默认会忽略isUserInteractionEnabled设置为NO、隐藏、alpha小于等于0.01的视图
if (!self.isUserInteractionEnabled || self.isHidden || self.alpha <= 0.01) {
return nil;
}
// 触摸点的绝对位置,在不在这个view里
if ([self pointInside:point withEvent:event]) {
// 从最顶层subview开始遍历
for (UIView *subview in [self.subviews reverseObjectEnumerator]) {
// 转换成以view为bounds的坐标
// 所以我认为toView比fromeView要合理
CGPoint convertedPoint = [subview convertPoint:point fromView:self];
UIView *hitTestView = [subview hitTest:convertedPoint withEvent:event];
if (hitTestView) {
return hitTestView;
}
}
return self;
}
return nil;
}
除了“扩大点击区域”,还有点击被遮挡的部分,或点击绘制区域以外的部分(没有裁剪的话绘制出去了仍会显示),总结一下:
pointInside:withEvent:方法只会被hitTest:withEvent:调用,这也是系统判断点击响应的默认途径- hitTest方法只会去测试当前视图的subview,如果你的控件绘制超出了本视图,即使
clipToBounds为NO,pointInside:withEvent:也不会被调用,因为点击区域在别的视图,它遍历不到你的控件 - 但是如果你是在viewcontroller的根视图,或共有的父视图上写的
hitTest方法,那么你是可以选择任意遍历顺序,甚至指定优先测试特定控件等一系列操作来判断点击位置是否在目标控件上的,这就是处理合并单元格区域里的按钮点击事件如日历视图里的跨越多天的事件时的核心技术手段 - 自行hitTest的时候,通常直接进行几何对比落点和目标矩形就行了,通常不需要再去关心目标控件的
pointInside方法是否有进行过变更,这主要是为了代码干净逻辑清晰,不然到处写了改变形状的代码,逻辑上就混乱了。实在要写的话,语法上确实是支持的。
最后,找到了响应者,最终的响应是以touchesBegan:withEvent:来落地的,如果没有实现,就会层层往上找实现者。所以UIController有默认的响应实现,并阻止了向上传播,而UIView的默认实现则是把事件往nextResponder转发(记住,不是没有实现)
userInteractionEnabled和手势识别器
设置userInteractionEnabled为YES,只是将该视图从hitTest的判断里排除掉了(所以如果你手写的代码没有去判断它,这个属性就形同虚设了)。真正让UIView能响应事件的,是你在打开这个属性后(让它能被hitTest认可为有效响应者),自行实现touchesBegan:withEvent:等方法,并返回YES,表示你愿意处理这个事件,并阻止事件向上传播。
或者
使用手势识别器来添加手势。手势识别器是触摸事件传播和响应机制的旁路系统。
- Hit-Testing 找到了你的 View:UIWindow 通过 hitTest 确认点击发生在你的 View 上。
- 手势识别器优先处理:UIWindow 将触摸事件首先交给了你的手势识别器。
- 手势识别成功:手势识别器分析触摸序列,判定这是一个有效的点击(UITapGestureRecognizer),状态变为 Recognized。
- 触发回调:手势识别器执行你的 @selector (Private) 方法,你的代码得以运行。
- 取消视图的响应:因为手势已经识别,UIWindow 不会再调用你的 View 的 touchesBegan 方法(即使你写了也不会被调用,或者会被 touchesCancelled 打断)
也就是说,使用手势系统,其实就是在拦截掉触摸事件,然后自己处理,而不会去调用touchesBegan等方法。
Runloop
- runloop是线程的基础架构部分,每个线程都有与之对象的runloop对象。
- 任意线程调用[NSRunLoop currentRunLoop]能获得相应的runlooop
- 子线程默认没有runloop, current方法反而开启了runloop
- mode用来指定事件的优先级
- 同时只能运行在一种mode下,需要停下切换
共5种mode:
- NSDefaultRunLoopMode (默认模式,有事件响应的时候,会阻塞旧事件)
- NSRunLoopCommonModes (普通模式,不会影响任何事件)
- UITrackingRunLoopMode (只能是有事件的时候才会响应的模式)
还有两种系统级别的模式 4. 一个是app刚启动的时候会执行一次 5. 另外一个是系统检测app各种事件的模式
给线程一个runloop就能让线程不死,最简单的实现:
@autoreleasepool{
[[NSRunLoop currentRunLoop] addPort:[NSPort port] forMode:NSDefaultRunLoopMode];
[[NSRunLoop currentRunLoop] run];
NSLog(@"threadBegin");//这句代码不会执行了,因为[[NSRunLoop currentRunLoop] run]一直在跑圈,在RunLoop内部会不断去查看该线程有没有任务要处理,若有,就让它处理一下
}
模态窗口与runloop
- 模态窗口不会卡死主线程,却能“挡住”背后的操作 —— 它不是靠 sleep,而是靠精细化的 Run Loop 控制。
- 这不是新建一个线程,而是在当前线程(通常是主线程)上,启动 Run Loop 的一个 嵌套循环
- 这个嵌套循环运行在 特定的 Run Loop Mode 中,通常是:
kCFRunLoopDefaultMode(对于普通模态)- 或
UITrackingRunLoopMode + Default的组合(视交互类型而定) - 或类似
NSModalPanelRunLoopMode(macOS 有,iOS 可能有等效机制)
@autoreleasepool (Private)
- 子线程中会默认包裹一个autoreleasepool的, 释放时机是当前线程退出的时候。
- 一个被autoreleasepool包裹生成得对象,都会在其创建生成之后自动添加autorelease, 然后被autorelease对象得释放时机 就是在当前runloop循环结束的时候自动释放的
- @autoreleasepool{} (Private) 本质上是一个结构体:
- autoreleasepool会被转换成__AtAutoreleasePool
- __AtAutoreleasePool 里面有两个函数objc_autoreleasePoolPush(),objc_autoreleasePoolPop().,其实一些列下来之后实际上调用得是* AutoreleasePoolPage类中得push 和 pop两个类方法
- push就是压栈操作,
- pop就是出栈操作于此同时对其对象发送release消息进行释放
NSTimer
几种Timer
这段代码放到子线程中会被执行吗?
[p performSelector:@selector(eat) withObject:nil afterDelay:4];
不会,这段代码创建了一个定时器放在了当前的runloop中,想要执行的话:[NSRunLoop currentRunLoop] run]一下
或者:[[NSRunLoop currentRunLoop]] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];(极少见)
原因,上述代码等同于:
[NSTimer scheduledTimerWithTimeInterval:4.0 target:p selector:@selector(eat) userInfo:nil repeats:NO];
scheduledTimer会自动将Timer添加到当前线程的runloop的Default Mode中- 但是,绝大多数子线程默认没有运行 RunLoop!((如
dispatch_queue、[NSThread detachNewThread])
而timer开头的方法, 连runloop都要自己添加
NSTimer *timer = [NSTimer timerWithTimeInterval:1.0 target:self selector:@selector(timerAction:) userInfo:nil repeats:YES];
// 顺带选一个mode
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
- timer开头的方法只是创建了一个
timer,而不是制定了一个schedule - timer默认是在
default mode,这样一旦切换到tracking mode,timer就会停止,所以需要添加到common mode里。原因是在 iOS 中,NSRunLoopCommonModes 通常包含了NSDefaultRunLoopMode和UITrackingRunLoopMode
初始化timer时用到的self会碰到循环引用问题搜索本文里的其它章节
- 通常情况下线程的作用是用来执行一个或多个特定的任务,在线程执行完成之后就会退出不再执行任务,RunLoop这样的循环机制会让线程能够不断地执行任务并不退出。
- RunLoop和线程是绑定在一起的,每条线程都有唯一一个与之对应的RunLoop对象。
- 不能自己创建RunLoop对象,但是可以获取系统提供的RunLoop对象。
- 主线程的RunLoop对象是由系统自动创建好的,在应用程序启动的时候会自动完成启动,而子线程中的RunLoop对象需要我们手动获取并启动。
- RunLoop在线程中不断检测,通过input source和timer source接受事件,然后通知线程进行处理事件。
- 一个RunLoop对象包含一个线程(_pthread),若干个mode(_modes),若干个commonMode(_commonModes)。
- RunLoop总是在某种特定的CFRunLoopMode下运行的,这个特定的mode便是_currentMode。
- 一个CFRunLoopMode对象有唯一一个name,若干个sources0事件,若干个sources1事件,若干个timer事件,若干个observer事件和若干port
CFRunLoopSource是输入源的抽象,分为source0和source1两个版本。
运行
- RunLoop的运行必定要指定一种mode,并且该mode必须注册任务事件。
- RunLoop是在默认mode下运行的,当然也可以指定一种mode运行,但是只能在一种mode下运行。
- RunLoop内部实际上是维护了一个do-while循环,线程就会一直留在这个循环里面,直到超时或者手动被停止。
- RunLoop 的核心就是一个 mach_msg() ,RunLoop 调用这个函数去接收消息,如果没有别人发送 port 消息过来,内核会将线程置于等待状态(基于port的source0,timer,手动唤醒等),否则线程处理事件。
苹果提到了以下几个model,并且只公开了第一个和最后一个:
- NSDefaultRunLoopMode:默认,大多数时候使用此模式来启动RunLoop并配置输入源。
- NSConnectionReplyMode:Cocoa将此模式与
NSConnection对象结合使用以监测回应。 - NSModalPanelRunLoopMode:Cocoa使用此模式来识别用于模式面板的事件。
- NSEventTrackingRunLoopMode:Cocoa使用此模式来限制鼠标拖动loop和其他类型的用户界面跟踪loop期间的传入事件。
- NSRunLoopCommonModes:是
NSDefaultRunLoopMode和NSEventTrackingRunLoopMode集合,在这种模式下RunLoop分别注册了NSDefaultRunLoopMode和UITrackingRunLoopMode(这又是哪来的,不是说只有5个吗)。当然也可以通过调用CFRunLoopAddCommonMode()方法将自定义Mode放到kCFRunLoopCommonModes组合
使用:
- 启动:
CFRunLoopRun和CFRunLoopRunInMode - 获取: CFRunLoopGetCurrent,CFRunLoopGetMain(在任意线程获取主线程runloop)
事件
__CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE0_PERFORM_FUNCTION__- to a source1 perform function
- to a block
- to a timer callback
- to an observer callback
- is serving the main dispatch queue (GCD主队列)
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
常驻线程
- (void)viewDidLoad {
[super viewDidLoad];
self.thread = [[NSThread alloc] initWithTarget:self selector:@selector(run) object:nil];
[self.thread start];
}
- (void)run {
NSRunLoop *currentRl = [NSRunLoop currentRunLoop];
// 确保 RunLoop 至少有一个事件源,从而不会立即退出。
[currentRl addPort:[NSPort port] forMode:NSDefaultRunLoopMode];
[currentRl run];
}
- (void)run2
{
NSLog(@"常驻线程");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event
{
[self performSelector:@selector(run2) onThread:self.thread withObject:nil waitUntilDone:NO];
}
你无法直接停止一个调用了 [runLoop run] 的线程。如果这个 ViewController 被销毁,self.thread 依然会继续运行,造成内存泄漏和资源浪费。
GCD定时器
- GCD 的定时器是直接跟系统内核挂钩的,而且它不依赖于RunLoop,所以它非常的准时
- 顺便演示了解决
self强引用的问题
__weak typeof(self) weakSelf = self;
dispatch_queue_t queue = dispatch_queue_create("SYLingGCDTimer", DISPATCH_QUEUE_CONCURRENT);
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, queue);
// leewayInSeconds 精准度
dispatch_source_set_timer(timer, DISPATCH_TIME_NOW, 1.0 * NSEC_PER_SEC, 0 * NSEC_PER_SEC);
dispatch_source_set_event_handler(timer, ^{
// code to be executed when timer fires
timer;
[weakSelf timerAction];
});
dispatch_resume(timer);
静态变量,常量,全局变量
- OC的静态变量不是类变量,只不过一直存在(只初始化一次)而已
- 只作用于当前.m文件
- 必须放在
@implementation外或方法中
- 常量关键字在星号前,修饰的是指针,地址不会变,但地址的内容可以变
- 所以写在变量名前才能保证是内容不变
- 拼到一起就是“静态常量”
- 函数外声明的就是全局的,定义的地方即赋初值的地方
- 要使用的地方加上extern声明一次
- 头文件中exetern的话,别的地方只需要导头文件了
.m 文件中 @implementation (Private) 外部的作用域是什么?
- 这是 C 语言的“文件作用域”(file scope),也叫“全局作用域”(但仅限于当前编译单元)
- Objective-C 是 C 的超集,.m 文件本质是一个 C 编译单元(translation unit)。
- 在
@implementation外部(包括#import下方、任何@implementation上方或下方)声明的变量,属于 C 的全局变量,但受 static 控制链接性。 - 它不是 Objective-C 的类成员,而是整个 .m 文件共享的 C 变量。
static要写在@implementation外部,是C语言特性而已,如果这个.m文件里写了多个实现体,那么客观上也就实现了共享这个静态变量。
在 Objective-C 中:
@interface ClassName () { ... }(Class Extension 中的花括号) 和@implementation ClassName { ... }(实现体中的花括号) 唯一的、共同的作用就是:声明实例变量,这个位置叫ivar块
static的位置
上面说了static声明的位置可以是方法体里(这样所有实例就共享了同一个变量),还可以是实现体外部,那么如果写到实现体内部呢?
如果写到内部(也只能写到ivar块,即implementation的花括号里),首先,如果不加static, 那么就是一个普通的实例变量,而如果你加了static,那就会报编译错误,因为它不属于任何实例,语义冲突了,一个是“整个程序一份”,一个是“每个实例一份”。
extern的语义是:
- 编译期看到这个符号,知道它不在本文件里, 链接期请到其它的目标文件(.o)或库里(全局符号表?)去找这个符号的定义。
大总结
- const可以在.h里定义,但只会有一种形态:
extern const xxxx,它必须在配套的.m里赋值。(编译的时候会写到全局符号表) - const可以在函数体里定义,等同于
Swift的let - const不可以在
ivar块内定义(因为不占用实例内存) extern过的常量,别的文件用,可以import, 也可以照猫画虎把extern写一遍,都能读出这个值(链接时都是去全局符号表找值) 4.1 在.m里声明的常量,即使不在配套.h里extern,别的文件自己extern也能用,适合“共享但不主动公开”的场景 4.2 本质的原因见下一节,在配套的.h里还是其它.h里extern为什么作用相同static修饰过const后,编译的时候不会写进全局符号表(进了文件局部表),缩小了可见范围 5.1. 其它文件无论是import还是extern,编译都能通过,但链接期就失败了(全局符号表找不到)static能在implementation外部定义,本文件可见,永存直到关掉appstatic能在方法体内部定义,实例化一次后永存,直到关掉app,函数外其它位置不可见static在.h文件里定义,别的文件import后, 那每个import它的文件拥有自己的同名static变量,互不影响(extern不行)static+const+extern在.h文件里,属于undefined behavior,引入了矛盾语义
编译和链接过程:
# 步骤1: 编译每个 .m 文件成 .o 文件
clang -c FileA.m -o FileA.o # FileA.o 包含 str1 的实际定义
clang -c FileB.m -o FileB.o # FileB.o 知道有 str1 这个东西(从 .h 得知)
clang -c FileC.m -o FileC.o # FileC.o 也知道有 str1(从手动 extern 得知)
# 步骤2: 链接所有 .o 文件成可执行文件
ld FileA.o FileB.o FileC.o -o program
链接时完全无关先后顺序!链接器会扫描所有 .o 文件两次:第一遍扫描:收集所有符号,第二遍扫描:解析所有引用。
没有事实上的“全局符号表”,而是叫
external linkage,代表:这个符号的名字对链接器可见,可以跨编译单元被引用或定义。 而“局部符号表”不同,链接器根本不关心它,它只存在于.o文件里供调试用。
小总结
C和OC里,文件作用域的裸变量,默认是external linkage.m文件里的const int a = 3就是这个意思
- 所以添加
extern起不到扩大作用域的作用,纯粹给编译器看的,告诉它这个变量在别的文件里,而链接的时候直接会在全局找- 即
.h文件里的extern const int a = 3
- 即
- 用
static修饰后,变成internal linkage - 函数内的
static语义完全变了(可以理解为共用了一个词),就是让数据活在数据段而不是栈里 - 在
.m配套的.h里和其它.h文件里extern一个常量,其实作用是一模一样的,它们能生效的原因完全就是第一点,即.m文件里在文件作用域声明了一个的变量,如果不带static,那就是在链接期能找到- 而用
import能得到这个这个常量,仅仅是它得到了extern这句话(本质)
- 而用
附加
上面说到,static的两种语义使得其更像是借了这个词而已,我们证明下:
static int s_value = 10; // 文件级 static(全局作用域)
@implementation MyClass
+ (void)test {
static int s_value = 20; // 函数级 static(局部作用域)
s_value++;
NSLog(@"局部: %d", s_value); // 21, 22, 23...
}
+ (int)getGlobal { return s_value; }
@end
输出:
[MyClass test]; // 局部: 21
[MyClass test]; // 局部: 22
[MyClass getGlobal]; // 10(文件级没变过)
说明同一个文件里,两种位置的static(缩小编辑范围,和移到数据段)各工作各的。
更不要说不同文件里声明同名
static变量了
数据段与堆的区别
数据段存的是“编译时就知道大小的静态数据”,堆存的是“运行时动态申请的数据”。
高地址
+------------------+
| 栈 (Stack) | ← 局部变量、函数调用、返回地址(向下增长)
+------------------+
| ↓ |
| ↑ |
+------------------+
| 堆 (Heap) | ← malloc/new、动态分配(向上增长)
+------------------+
| BSS 段 (BSS) | ← 未初始化的全局/静态变量(自动清零)
+------------------+
| 数据段 (Data) | ← 已初始化的全局/静态变量
+------------------+
| 代码段 (Text) | ← 程序指令、只读常量
+------------------+
低地址
block
block是一种可在C、C++及OC代码中使用的“词法闭包”(lexical closure),它极为有用,借此机制,开发者可将代码像对象一样传递,令其在不同环境(context)下运行。在block的范围内,它可以访问到其中的全部变量。
- 能修改外部变量不单靠_block关键字,还能对可变属性进行更改
- 所谓的由栈复制到了堆
- 但其实是用了一种语法,提供了“更改只读变量”的途径
- 动画的block不是真的block,只是语法上告知了最终状态,让动画去计算插值
- 单例的block由单例对象的持有
- block里引了self并不一定造成引用循环,要看block本身有没有被强引用
- Blocks are
Objective-Cobjects- they can be added to collections like
NSArrayorNSDictionary. - can capture values from the enclosing scope
- but their memory management situation is somewhat unique.
- Most of the time you won’t need to
copyorretaina block at all.
- they can be added to collections like
- track block:
@property (copy) void (^blockProperty)(void); - Blocks maintain
strong referencesto any captured objects, includingself
栈堆同步
__block处理的是本地捕获的变量一定是产生在栈上的,而作为类属性等赋值后,block却已经在堆里了,是如何同步的问题.- 解决方式是把修饰的变量变成了一个结构体:
struct __Block_byref_str {
void *__isa;
struct __Block_byref_str *__forwarding; // 转发指针
int __flags;
int __size;
// 下面是真实的值(也就是原本这个变量被修饰前的值)
NSMutableString *str; // 如果是个string
int value; // 如果是个int
};
__block修饰后,生成的上述结构体替换了原本的变量__forwarding指向的是结构体本身- 一理包含该变量的
block被复制到了堆上,就有了两个结构体,一个在栈上,一个在堆上 - 堆上那个
__forwarding指向的是自己 - 栈上那个
__forwarding指向的是堆上的那个结构体的地址
同上此实现的数据的同步。可以说,__block的机制就是增加一层间接寻址。
也就是说,一旦发生复制,留在栈上的结构体,唯一有用的就是那个
__forwarding了,存值的那个字段也没意义了。
copy到堆的时机
在 ARC 下,你很少需要手动 Block_copy() 或 [block copy],因为:
- 把 Block 赋值给 strong 属性时,编译器自动执行 copy
- 把 Block 作为返回值时,编译器自动执行 copy
- 栈 Block 在 ARC 下几乎不会出现(编译器会帮你拷贝到堆)
blcok捕获对象变量
思考: 通过
__block修饰的变量,在block发生复制后,实现了数据同步,但是如果本来就是一个对象,那它本来就是在堆上,有必要__block吗?
也是要的。
- 你直接把生成的对象地址给block,那你就只能修改这个对象,却不能将它再指向别人了
- 我用
__block,是新生成了一个变量来指向这个地址,而这个变量,也是可以指向其它地址的。
注意两者的区别,即捕获了对象还是捕获了对象的引用. 或者说,给对象加__block,不是为了“复制到堆上”,而是为了允许修改指针的。
Category & Extention
- 在Runtime中,objc_class结构体大小是固定的,不可能往这个结构体中添加数据,只能修改。
- ivars指向的是一个固定区域,只能修改成员变量值,不能增加成员变量个数。(编译时固定,通过通过第一个变量的地址不断offset来读取所有)
- methodList是一个二维数组,所以可以修改
*methodLists的值来增加成员方法。- 虽没办法扩展methodLists指向的内存区域,却可以改变这个内存区域的值(存储的是指针)。
因此,可以动态添加方法(其实已经很复杂了,每次添加后都是指向了一个全新的数组),不能添加成员变量。
typedef struct category_t {
const char *name; //类的名字
classref_t cls; //类
struct method_list_t *instanceMethods; //category中所有给类添加的实例方法的列表
struct method_list_t *classMethods; //category中所有添加的类方法的列表
struct protocol_list_t *protocols; //category实现的所有协议的列表
struct property_list_t *instanceProperties; //category中添加的所有属性
} category_t;
- category的定义可见,能添加属性,但不能添加成员变量
- 所以只能生成getter, setter(的方法声明),却不会生成相应的成员变量,(所以没有实现)
- 所以只能到runtime里用关联对象来实现
category和原来类都有methodA,那么category附加完成之后,类的方法列表里会有两个methodA。 主类的方法被分类的foo覆盖了,其实分类并没有覆盖主类的foo方法,只是分类的方法排在方法列表前面,主类的方法列表被
挤到了后面, 调用的时候会首先找到第一次出现的方法。 如果想要只是执行主类的方法,可逆序遍历方法列表,第一次遍历到的foo方法就是主类的方法。class_copyMethodList([target class], &count)
类在内存中的位置是编译时期决定的, 之后再修改代码也不会改变内存中的位置,class_ro_t 的属性在运行期间就不能再改变了, 再添加方法是会修改class_rw_t 的methods 而不是class_ro_t 中的 baseMethods
.m文件里的
@interface MyClass ()
@property (nonatomic, strong) NSObject *obj;
@end
与
@interface MyClass: NSObject
@property (nonatomic, strong) NSObject *obj;
@end
是不一样的,
-
后者就是类声明,有一个叫obj的属性
-
前者是一个Extension
-
extension常用的形式并不是以一个单独的.h文件存在,而是寄生在类的.m文件中。如上例
-
extension在编译的时候,它的数据就已包含在类信息中。category是在运行时,才会将数据合并到类信息中。
-
extension可以添加成员变量,而category是无法添加成员变量。
- 因为在运行期,对象的内存布局已经确定,如果添加成员变量就会破坏类的内部布局,这对编译型语言来说是灾难性的。
-
extension一般用来隐藏类的私有信息,无法直接为系统的类扩展,但可以先创建系统类的子类再添加extension。category可以给系统提供的类添加分类。
-
extension和category都可以添加属性,但是category的属性不能生成成员变量和getter、setter方法的实现。
多继承
https://juejin.cn/post/6847902215923990536
- 通过组合实现多继承;
- 每个父类一个属性,初始化的时候把每个父类实例化好
- 找到每个方法对应的父类实例,来调用相应方法
- 通过协议实现多继承;
- 每个父类实现相应的协议
- 每个父类一个属性,实例化好
- 实现协议方法时调用相应的实例化好的父类方法
- 通过类别实现多继承;
- 通过category和associated object,让类拥有了父类(其实也是作为成员变量/属性)
- 通过Runtime消息转发实现多继承;
- 通过NSProxy实现多继承;
可见,大多数实现是你想继承什么类,就让这个类的实例成为你的一个属性。
load 和 initilze
+initialize方法的调用方式为消息机制,而非像+load那样直接通过函数地址调用。
NSCache
- 类似可变字典一样(一个cache对应一个key),
- 但是NSCache是线程安全的, 系统类自动做好了加锁和释放锁等一系列的操作,
- 还有一个重要的是如果内存不足的时候NSCache会自动释放掉存储的对象,不需要开发者手动干预。
- 或者手动设定缓存key的上限(FIFO)->
countLimit- 及缓存容量的上限 ->
totalCostLimit - 所以取cache需要判断是否为空
- 及缓存容量的上限 ->
会释放cache的场景: 回答之前,先说一情况,在某C中创建了NSCache对象,点击手机的Home或者任何方式进入后台,会发现NSCache中的代理方法被执行了,于是NSCache对象会释放掉所有对象,还有的是,如果发生内存警告也会释放掉所有对象。所以, 这道题应该如下这么回答!
- NSCache自身释放了,其中存储的对象也就释放了。
- 手动调用释放方法removeObjectForKey、removeAllObjects
- 缓存对象个数大于countLimit
- 缓存总消耗大于totalCostLimit
- 程序进入后台
- 收到内存警告
ViewController生命周期
- initWithCoder:通过nib文件初始化时触发。
- awakeFromNib:nib文件被加载的时候,会发生一个awakeFromNib的消息到nib文件中的每个对象。
- loadView:开始加载视图控制器自带的view。
- viewDidLoad:视图控制器的view被加载完成。
- viewWillAppear:视图控制器的view将要显示在window上。
- updateViewConstraints:视图控制器的view开始更新AutoLayout约束。
- viewWillLayoutSubviews:视图控制器的view将要更新内容视图的位置。
- viewDidLayoutSubviews:视图控制器的view已经更新视图的位置。
- viewDidAppear:视图控制器的view已经展示到window上。
- viewWillDisappear:视图控制器的view将要从window上消失。
- viewDidDisappear:视图控制器的view已经从window上消失。
渲染机制
iOS渲染视图的核心是Core Animation,其渲染层次依次为:图层树->呈现树->渲染树, 一共三个阶段
- CPU阶段
- 进行Frame布局,准备视图和图层之间的层级关系)
- CPU会将处理视图和图层的层级关系打包,通过IPC(进程间的通信)通道提交给渲染服务(OpenGL和GPU)
- OpenGL ES阶段(iOS8以后改成Metal)
- 进行纹理生成和着色,生成前后帧缓存
- 再根据硬件的刷新帧率,一般以设备的VSync信号和CADisplayLink(类似一个刷新UI专用的定时器)为标准,进行前后帧缓存的切换
- GPU阶段
- 要显示在画面上的后帧缓存交给GPU,进行采集图片和形状,运行变换, 应用纹理混合,最终显示在屏幕上。
- GPU渲染负担的一般是:
离屏渲染,图层混合,延迟加载。
图片显示分为三个步骤: 加载、解码、渲染、 通常,我们程序员的操作只是加载,至于解码和渲染是由UIKit内部进行的。
UIImage持有的数据是未解码的压缩数据,赋值的时候才会解码(成RGB颜色数据)。
离屏渲染
笼统理解的话,就像自旋锁和互斥锁的区别,需要切换上下文的场景都是有消耗的。
- 光栅化 layer.shouldRasterize = YES
- 遮罩layer.mask
- 圆角layer.maskToBounds = Yes,Layer.cornerRadis 大于0
- 阴影layer.shadowXXX
Core Animation
Core Animation 在 RunLoop 中注册了一个 Observer,监听了 BeforeWaiting 和 Exit 事件。这个 Observer 的优先级是 2000000,低于常见的其他 Observer。
当一个触摸事件到来时,RunLoop 被唤醒,App 中的代码会执行一些操作,比如创建和调整视图层级、设置 UIView 的 frame、修改 CALayer 的透明度、为视图添加一个动画;
这些操作最终都会被 CALayer 捕获,并通过 CATransaction 提交到一个中间状态去(CATransaction 的文档略有提到这些内容,但并不完整)。
当上面所有操作结束后,RunLoop 即将进入休眠(或者退出)时,关注该事件的 Observer 都会得到通知。这时 CA 注册的那个 Observer 就会在回调中,把所有的中间状态合并提交到 GPU 去显示;如果此处有动画,CA 会通过 DisplayLink 等机制多次触发相关流程。
iOS 新特性
iOS9
* 从HTTP升级到HTTPS
* App瘦身 下面有讲 这里不赘述( App瘦身 )
* 新增UIStackView
iOS10
* 新增通知推送相关的操作。自定义通知弹窗,自定义通知类型(地理位置,时间间隔,日历等)
iOS11
* 无线 调试
* 齐刘海儿,导航条,安全距离等
- iOS12
- iOS13
- 黑暗模式
瘦身
- APP Slicing
- 上传itunes connect的自动过程,会把资源针对机型进行打包,不需要的资源就抛弃了,比如@2x, @3x这样的,完全不需要冗余
- 不需要开发者干预
- Bitcode
- 也是上传后苹果对可执行文件进行了优化和重编译,不需要开发者干预
- ODR(on demand resource)
- 上传的时候会根据配置把相关资源抽离,调用到的时候即时下载
- 需要开发者配合编码
KVC
当调用setValue:forKey:时:
- 程序优先调用
set<Key>:属性值方法,代码通过setter方法完成设置。- 注意,这里的
是指成员变量名,首字母大小写要符合KVC的命名规则,下同
- 注意,这里的
- 如果没有找到
set<Key>:方法,KVC机制会检查+(BOOL)accessInstanceVariablesDirectly方法有没有返回YES- 默认该方法会返回YES,
- 如果你重写了该方法让其返回NO的话,那么在这一步KVC会执行
setValue:forUndefinedKey:方法,不过一般开发者不会这么做。
- 搜索该类里面有没有名为
_<key>的成员变量,无论该变量是在类接口处定义,还是在类实现处定义,也无论用了什么样的访问修饰符,只要存在以_<key>命名的变量,KVC都可以对该成员变量赋值。 - 如果该类既没有
set<key>:方法,也没有_<key>成员变量,KVC机制会搜索_is<Key>的成员变量。 - 如果该类既没有
set<Key>:方法,也没有_<key>和_is<Key>成员变量,KVC机制再会继续搜索<key>和is<Key>的成员变量。再给它们赋值。 - 如果上面列出的方法或者成员变量都不存在,系统将会执行该对象的
setValue:forUndefinedKey:方法,默认是抛出异常。
即如果没有找到set<Key>方法的话,会按照_key,_iskey,key,iskey的顺序搜索成员并进行赋值操作。
当调用valueForKey:时,KVC对key的搜索方式不同于setValue:forKey:,其搜索方式如下:
- 首先按
get<Key>,<key>,is<Key>的顺序方法查找getter方法,找到的话会直接调用。- 如果是
BOOL或者Int等值类型, 会将其包装成一个NSNumber对象。
- 如果是
- 如果上面的getter没有找到,KVC则会查找
countOf<Key>,objectIn<Key>AtIndex或<Key>AtIndexes格式的方法。- 如果
countOf<Key>方法和另外两个方法中的一个被找到,那么就会返回一个可以响应NSArray所有方法的代理集合(它是NSKeyValueArray,是NSArray的子类),调用这个代理集合的方法,或者说给这个代理集合发送属于NSArray的方法,就会以countOf<Key>,objectIn<Key>AtIndex或<Key>AtIndexes这几个方法组合的形式调用。还有一个可选的get<Key>:range:方法。 - 所以你想重新定义KVC的一些功能,你可以添加这些方法,需要注意的是你的方法名要符合KVC的标准命名方法,包括方法签名。
- 如果
- 如果上面的方法没有找到,那么会同时查找
countOf<Key>,enumeratorOf<Key>,memberOf<Key>格式的方法。- 如果这三个方法都找到,那么就返回一个可以响应
NSSet所的方法的代理集合,和上面一样,给这个代理集合发NSSet的消息,就会以countOf<Key>,enumeratorOf<Key>,memberOf<Key>组合的形式调用。
- 如果这三个方法都找到,那么就返回一个可以响应
- 如果还没有找到,再检查类方法
+(BOOL)accessInstanceVariablesDirectly, 如果返回YES(默认行为),那么和先前的设值一样,会按_<key>,_is<Key>,<key>,is<Key>的顺序搜索成员变量名- 这里不推荐这么做,因为这样直接访问实例变量破坏了封装性,使代码更脆弱。
- 如果重写了类方法
+(BOOL)accessInstanceVariablesDirectly返回NO的话,那么会直接调用valueForUndefinedKey:方法,默认是抛出异常。
堆/栈/内存/缓存
malloc出来的就是heap,它有两种场景会释放:
- The memory is free'd
- The program terminates
如果这块内存区域没有任何指针指向它,就是memory leak
This is where the memory has still been allocated, but you have no easy way of accessing it anymore. Leaked memory cannot be reclaimed for future memory allocations, but when the program ends the memory will be free'd up by the operating system.
stack memory which is where local variables (those defined within a method) live. Memory allocated on the stack generally only lives until the function returns (there are some exceptions to this, e.g. static local variables).
数据类型都有固定的大小,因此编译时就能能知道(根据编译环境)。访问时只需要用offset就能访问到这些栈上的变量,而不是pop出来使用。
堆和栈都是内存,只是分配方式不同。 堆:动态分配,大小不固定,需要手动释放,比如new对象,数组等 栈:静态分配,大小固定,不需要手动释放,比如函数调用,局部变量等
- 栈和堆都是放在内存。就是RAM,通常所说的内存条!因为程序运行就是在运行在内存里的!
- 栈:栈是先进后出(FILO),比如函数调用,函数的参数和局部变量都会被压入栈,函数执行完毕,参数和局部变量会从栈中弹出,所以栈的大小是静态的,是编译时就知道的,比如数组的大小,每个程序允许申请的栈大小是有上限的,数组申请过大,会导致栈溢出Q!
- 堆:堆的大小是动态的,程序运行是动态申请的,不固定,比如new对象的个数和大小!需要自己手动释放,不然会导致内存泄漏!
所以说ARC下block会被复制到堆上, 意思就是函数生命周期结束后, 这个block并不会被释放
栈存在的意义
- 程序不仅仅是由数据构成,还包括处理数据的逻辑方法。
- 而这些方法的编码和执行顺序是非常符合后出先进的设计逻辑。因此栈的存在更多是为程序的方法服务
- 方法中的临时变量存在栈中, 理论上这些变量全部在堆(Heap)中生成也是可行的。
- 在栈中存储有两个优势
- 一个是由于栈的特性,栈中的方法执行完后,会实时从栈顶移除。栈中的临时变量的声明周期也因此结束,内存释放效率非常高。
- 另一方面,栈的大小通常是固定的,
ulimit -s查看下, 只有8M, 原因:- 栈的调用,也就是程序执行的速度,不仅仅依赖于CPU,也同样依赖内存的读取速度。
- 所以栈的存储会依赖于大小有限的高速缓存,如果栈过大,则高速缓存会出现大量内存空间的交换,反而降低了执行的速度。
- 所以珍贵有限的栈空间,就应该尽量避免存储容量大或者声明周期长的数据。
所以堆(Heap)就有它存在的场景了,内存空间大,数据存在时间长 (依赖于不同的内存释放策略),通过地址引用,也相对松散。
缓存分为两种:程序缓存和CPU缓存
- 程序缓存:就是所说的缓冲区!栈和堆都属于程序缓存!让数据保存在内存中,加快程序计算效率的!(说法:栈属于一级缓存、堆属于二级缓存)
- CPU缓存:这是硬件层次缓存,处于内存条和CPU之间,以为比如CPU的L1L2L3等缓存机制,因为CPU缓存比CPU读内存数据更快! 用于存放热点数据,数据如何分级存放有自己的算法。
面试相关
property
- @property (Private) = ivar + getter + setter; (实例变量+存取方法)
- 完成属性定义后,编译器会自动编写访问这些属性所需的方法,此过程叫做“自动合成”( autosynthesis)。
- 编译器还要自动向类中添加适当类型的实例变量,并且在属性名前面加下划线
- @synthesize的语义是如果你没有手动实现setter方法和getter方法,那么编译器会自动为你加上这两个方法。 (Private)
- @dynamic的语义是告诉编译器:属性的setter与getter方法由用户自己实现,不自动生成。 (Private)
对于属性foo,
- 如果是 @synthesize (Private) foo; 还会生成一个名称为foo的成员变量
- 如果是 @synthesize (Private) foo = _foo; 就不会生成成员变量了
一个属性生成的东西
- OBJCIVAR属性名称 :该属性的“偏移量” (offset),这个偏移量是“硬编码” (hardcode),表示该变量距离存放对象的内存区域的起始地址有多远。
- setter与getter方法对应的实现函数
- ivar_list :成员变量列表
- method_list :方法列表
- prop_list :属性列表
也就是说我们每次在增加一个属性,系统都会
- 在ivar_list中添加一个成员变量的描述,
- 在method_list中增加setter与getter方法的描述,
- 在prop_list中增加一个属性的描述,
- 然后计算该属性在对象中的偏移量,
- 然后给出setter与getter方法对应的实现,
- 在setter方法中从偏移量的位置开始赋值,
- 在getter方法中从偏移量开始取值,
- 为了能够读取正确字节数,系统对象偏移量的指针类型进行了类型强转.
weak和assign
- 既不保留新值,也不释放旧值。此特质同assign类似,
- 然而在属性所指的对象遭到摧毁时,属性值也会清空(nil out)。
- runtime 对注册的类, 会进行布局:
- 对于 weak 对象会放入一个 hash 表中。
- 用 weak 指向的对象内存地址作为 key,当此对象的引用计数为0的会找到所有weak引用,然后自动置
nil
super和self
- 两者指向的都是self, 假如一个Father, 一个Son
- super多一个功能,就是告诉编译器,找方法时去父类找,而不是它指向super, 即[super class]=[self class]= Son
- 即使是self,在本身找不到方法时,也会从父类找(用super直接从父类开始找了而已)
- self转成id objc_msgSend(id self, SEL op, ..)
- super转成id objc_msgsendSuper(struct objc_super *super, SEL op, ...)
class方法:
- [self class]:
- Son里没有,Father里没有,NSObject里找到了,实现是: return object_getClass(self) -> SON
- [super class]:
- 先构造结构体(receiver, class)
- receiver: 就是self
- class: (id)class_getSuperclass(objc_getClass("Son")) => Father
- Father类里,没找到class方法,继续,NSObject类里找
- objc_msgsend(objc_super->receiver, @selector (Private)(class)), 等同于[Son class]了
- 先构造结构体(receiver, class)
总结:
super只是告诉你找方法的起始位置, 而且找的只是方法的"逻辑", 而不是把指针指向了super. 所以用super调的任何方法, 意思就是到super里把代码找出来, 但还是由我来执行. 那么代码里写的任何逻辑, 仍然是作用当前类实例的.
离屏渲染
- 正常 app » frame buffer » display
- 离屏 app » off screen frame buffer » frame buffer » display
- 可以打开Xcode -> Debug -> View Debuging -> Rendering -> Color Offscreen Rendered Yellow开关来显示(真机)
- 模拟器 debug -> Color Off-screen Rendered
- 黄色区域表示发生了离屏渲染。不过在实际测试过程中,有出现绿色的区域,猜想可能和Color Hits Green and Misses Red一样,表示复用了光珊化的离屏渲染缓存。
- 对于投影:如果单纯设置shadowOffset,会触发离屏渲染,但是我们可以设置shadowPath,告诉Core Animation投影路径,那么系统就知道如何绘制投影了,就不会触发离屏渲染了。
- 对于裁剪:单独cornerRadius+masksToBounds不一定产生离屏渲染
- 只要有多个layer就会触发(比如uibutton设置了bgcolor, 和image,它们就分属多个layer)
- 尽量不用不必要的mask
- layer 设置了组不透明度allowsGroupOpacity,并且不透明度opacity小于1。会触发
画家算法
- 也叫作优先填充,它是三维计算机图形学中处理可见性问题的一种解决方法(三维场景投影到二维平面)。画家算法首先将场景中的多边形根据深度进行排序,然后按照由远到近的顺序进行描绘,
- 这种方法通常会将不可见的部分覆盖,这样就可以解决可见性问题。
- 对于有前后依赖的图层(如阴影叠加、裁剪等),通过由远到近的图层叠加算法是无法实现的(即后叠加的图层不是一个独立图层能够直接覆盖上去)
- 所以申请一个临时缓冲区,对所有图层应用画家算法,最后再总体对这个缓冲区进行阴影和裁剪,再交给当前缓冲区提供给显示器
New Interview
CADisplayLink
- CADisplayLink是一个能让我们以和屏幕刷新率相同的频率将内容画到屏幕上的定时器。
- 比NSTimer更精确, 但仍依赖于
Runloop, 任务过于繁重仍然会掉帧 - GCD不依赖
Runloop
- 比NSTimer更精确, 但仍依赖于
- 创建一个新的CADisplayLink对象,把它添加到一个
runloop中,并给它提供一个target和selector在屏幕刷新的时候调用。 target可以读到CADisplayLink的每次调用的时间戳,用来准备下一帧显示需要的数据。- 例如一个视频应用使用时间戳来计算下一帧要显示的视频数据。
- 在UI做动画的过程中,需要通过时间戳来计算UI对象在动画的下一帧要更新的大小等等。
- 在添加进runloop的时候我们应该选用高一些的优先级,来保证动画的平滑
- 它的定时机制是屏幕刷新, Timer是设定的周期
- 使用场合相对专一,适合做UI的不停重绘,比如自定义动画引擎或者视频播放的渲染。
Timer中的Target和self的循环引用 article
[self.timer invalidate] + self.timer= nil配合, 一定能打破循环引用(CADisplayLink同理), 但是:
- 如果
timer在Runloop中,那么Runloop会等timer执行完再调用dealloc, - 所以根本执行不到这个方法
- (void)dealloc{
[self.timer invalidate];
}
- 在外部/别的时机
invalidate, 比如viewWillDisappear - 换成block
- 加个中间类, 设置一个
weak属性指向self, 参考 - 用NSProxy, 原理由3, 引用一个
weak target, 然后把两个核心方法都转发给target
换block是iOS10以后的新方法:
+ (NSTimer *)timerWithTimeInterval:(NSTimeInterval)interval repeats:(BOOL)repeats block:(void (^)(NSTimer *timer))block API_AVAILABLE(macosx(10.12), ios(10.0), watchos(3.0), tvos(10.0));
+ (NSTimer *)scheduledTimerWithTimeInterval:(NSTimeInterval)interval repeats:(BOOL)repeats block:(void (^)(NSTimer *timer))block API_AVAILABLE(macosx(10.12), ios(10.0), watchos(3.0), tvos(10.0));
NSProxy
- NSProxy实现了NSObject协议
- 是所有代理类的基类,它是一个抽象类,不能直接使用,必须继承它才能使用
- 它接收到任何自己没有定义的方法他都会产生一个异常, 从而走上消息转发的路径
- 看看它的几个方法:
- 必须实现的方法:
- (void)forwardInvocation:(NSInvocation *)anInvocation;,这个方法用来将消息转发给其他对象。 - 还提供了一个方法:
- (nullable NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector;,这个方法用来返回一个方法签名,这个方法签名会传递给forwardInvocation:方法中的NSInvocation对象,用来表示将要转发的方法。 - 这两个就是消息转发机制里的兜底方法嘛, 所以它的作用主要就是用来转发消息
- 必须实现的方法:
- NSInvocation是Objective-C中用来表示一个方法调用的类,它包含了方法调用的所有信息,包括目标对象、方法选择器、参数等。NSInvocation类提供了一些方法,可以用来设置和获取这些信息,还可以用来调用方法。
- NSMethodSignature是Objective-C中用来表示一个方法签名的类,它包含了方法的返回值类型、参数类型等信息。NSMethodSignature类提供了一些方法,可以用来获取这些信息。
与NSObject的区别
- NSObject如果没找到方法, 会按
resolve,fast forward,invocation的顺序来处理 - NSProxy直接就最后一步了
Pod
使用zip打包的三方库
- 编辑
xxx.podspec文件:
s.source = { :http => 'URL', :type => 'zip' }
扩展一下:
- :git => :tag, :branch, :commit, :submodules
- :svn => :folder, :tag, :revision
- :hg => :revision
- :http => :flatten, :type, :sha256, :sha1, :headers
这种方式需要把podspec文件推到repo服务器, 比如github的/CocoaPods/Specs目录下, 其实也可以直接在podfile里指定本地podfile路径:
pod 'XxxSDK', :podspec => './'
为什么不用:path呢? 因为
path默认你指向的就是源码, 是用来开发的(而不是部署的)和本地调试的, 所以会忽略source配置项
- 在
podfile里直接写 这篇文章里讲了导入XCFramework打成了zip包的方式, 包含了需要鉴权的写法:
pod 'GreatSDK', :http => 'https://codetitans.pl/sdk/GreatSDK_1.0.1.zip',
type: :zip, :headers => ['Authorization: Basic <access_info>', 'Accept: application/octet-stream']
pod 'GreatSDK', :http => 'https://api.github.com/repos/phofman/great-sdk-ios/releases/assets/312344508',
type: :zip, :headers => ['Authorization: token <token_with_full_repo_access>', 'Accept: application/octet-stream']
Swift
final限制类的继承, 属性/方法的重写, 类似sealed
Static v.s. Class
- 都可以用来声明类型级别的属性和方法(静态成员)
static比class多了结构体和枚举的应用场景- static不能被子类重写, class可以
- static修饰的类方法和属性包含了final关键字的特性,重写会报错
访问控制
- 默认(即不写的话)是
internal模块内访问,一般用于内部实现,即没有特殊要求,外部也看不到 fileprivate文件内访问,比internal更具体的实现, 明确知道只是为当前文件写的private主动控制只被当前的类/结构体访问public可以被任何地方访问, 但是不能被继承和重写, 对外SDK, lib基本用这个open如果希望能被继承和重写, 则需要open
Swift Any、AnyObject和Generics区别
- Any是一个协议(protocol), 也是一个特殊类型
- 可以存储任意类型(包括值类型)
- 编辑器会放弃类型检查
- AnyObject限定了必须是引用类型(类类型), 不能存储结构体, 枚举及其它类型
- Generics 可以是任意类型, 但编译时会进行类型检查, 因为调用者的类型已经是确定的了
泛型
- 可以用于函数、方法、类、结构体和枚举等地方
- 泛型协议:
protocol a<T> {} - 泛型类型:
class MyClass<T> {}- 给它写扩展的时候, 这个T仍然是是可用的
- 协议通过关联类型
associatedtype T而不是尖括号来实现
- 泛型协议:
- 泛型约束
T:xxxx, 可以是协议, 也可以是类
func findIndex<T: Equatable>(of valueToFind: T, in array:[T]) -> Int? {
for (index, value) in array.enumerated() {
if value == valueToFind {
return index
}
}
return nil
}
这里, 你不加约束的话, 不能保证传进来的T都是可比较的
protocol Container {
associatedtype ItemType: Equatable // 这里要使用类型的地方, 先定义一个占位符, (同样可以加约束)
mutating func append(_ item: ItemType)
var count: Int { get }
subscript(i: Int) -> ItemType { get }
}
// 使用, 在adopt它的类型/结构体的地方仍然还是以尖括号传入
struct Stack<Element>: Container {
// original Stack<Element> implementation
var items = [Element]()
mutating func push(_ item: Element) {
items.append(item)
}
mutating func pop() -> Element {
return items.removeLast()
}
// conformance to the Container protocol
// 看, 直接使用Element占位符就行了
mutating func append(_ item: Element) {
self.push(item)
}
var count: Int {
return items.count
}
subscript(i: Int) -> Element {
return items[i]
}
}
更复杂的协议约束,
protocol SuffixableContainer: Container {
// where里面的==说的是类型相等
associatedtype Suffix: SuffixableContainer where Suffix.Item == Item
func suffix(_ size: Int) -> Suffix
}
Extension
Swift Extensions 可以为现有的类添加方法、结构体、枚举或协议:
- 添加计算型属性和计算静态属性
var v {...} - 定义实例方法和类型方法
func a() {} - 提供新的构造器
init() - 给protocol提供默认实现
- 定义下标
subscript(var idx: Int) -> T {} - 修改实例方法
mutating func square() {} - 定义嵌套类型, 跟定义在主类是一样的, 需要使用点语法来访问
- 使一个已有类型符合某个协议, 比如各种
delegate,dataSource都写在extension里
不能做的:
- 不能添加存储属性(可以用关联对象模拟,但这不是 Swift 的方式)
- 不能重写现有方法(只能添加新方法)
- 不能添加指定构造器或 deinit
- 不能改变原有的访问控制级别
- 不能添加 required 构造器(特定情况下)
使用assocate object添加存储属性:
// 方法一:
// 定义在外部
private var key: Void?
extension MyClass{
var b:String? {
get{
objc_getAssociatedObject(self, &key) as? String
}
set{
objc_setAssociatedObject(self, &key, newValue, .OBJC_ASSOCIATION_RETAIN_NONATOMIC)
}
}
}
// 方法二:
public extension UIView {
// 定义到内部, 用struct包一下
private struct AssociatedKey {
static var identifier: String = "identifier"
}
public var identifier: String {
get {
return objc_getAssociatedObject(self, &AssociatedKey.identifier) as? String ?? ""
}
set {
objc_setAssociatedObject(self, &AssociatedKey.identifier, newValue, .OBJC_ASSOCIATION_COPY_NONATOMIC)
}
}
}
extension中使用约束
extension Set where Element == String {
// 在这里添加你的方法
func yourCustomMethod() -> Void {
// 方法实现
}
}
上面的Element不仅仅是个占位符号, 它的语义是描述的对象必须是个集合(比如Set), 而我代表的是这个集合里的元素
线程同步
- 锁, 如
NSLock - 条件变量, 如
pthread_cond_t - 信号量, 如
dispatch_semaphore_t - 屏障, 栅栏, 如
dispatch_barrier_async - 队列,
dispatch_group_enter,dispatch_group_leave - Actor, Swift Concurrency:Swift 5.5引入的并发模型,支持Actor模型。
信号量
let sema = DispatchSemaphore(value: 0)
DispatchQueue.global().async {
sema.wait()
print("1")
}
DispatchQueue.global().async {
sleep(UInt32(2))
print("2")
sema.signal()
}
//打印输出为 2,1
DispatchSemaphore的初始值为0,表示当前信号量不可用,调用wait方法会阻塞当前线程,直到信号量可用。signal方法释放信号量,使信号量变为可用状态。- 所以
wait只会在信号量为0时才阻塞运行 - 上述用例中, 一个线程里在wait, 一个线程在两秒后signal
本质上
wait是把信号量减1,signal是把信号量加1, 小于0时, 就阻塞了.
应用:
如果用来当作线程同步, 初始值应该为0, 在需要同步的位置添加对应数量的wait, 在每个任务完成的时候才释放:
dispatch_semaphore_t dsema = dispatch_semaphore_create(0);
dispatch_async(self.concurrentQueue, ^{ // 独立的任务一
sleep(self.taskTime);
dispatch_semaphore_signal(dsema);
});
dispatch_async(self.concurrentQueue, ^{ // 独立的任务二
sleep(self.taskTime);
dispatch_semaphore_signal(dsema);
});
dispatch_semaphore_wait(dsema, DISPATCH_TIME_FOREVER);
dispatch_semaphore_wait(dsema, DISPATCH_TIME_FOREVER);
// 两个独立的任务都执行完成后, 再执行后续任务
// ...
- 因为初始值为0, 所以一wait就是减1了, 线程阻塞
- 因为初始值为0, 所以把wait写到最task前面也是没问题的 (采用这种写法, 结合wait就是减1的认知, 可能代码更易懂, 比先写task再wait更好理解)
- 本例中,
wait了两次, 所以只能持续收到2个signal信号, 才会继续执行后续任务
如果是用来给资源加锁(或设置资源池):
- 首先, 加锁和资源池的意义是一样的, 资源池等于1时就叫加锁了, 因为只要有1个人使用, 就达到上限了.
- 初始值设为
n, 每次使用前先wait一下, 把自己的指标拿走- 注意,
wait后能会不会阻塞是看减1后的结果, 所以初始值至少要为1
- 注意,
- 每次使用完资源后, 再
signal一下, 把指标还回去
多数情况下我们设的就是1, 即独占, 防止racing, 设为大于1的场景一般是限制资源消耗, 比如数据库连接池, 线程池等.
Group版本的线程同步则不需要关心0和1这样的, 只需要保证enter和leave的数量一致即可, 比如上面的例子可以改成:
dispatch_group_t group = dispatch_group_create();
dispatch_group_enter(group);
dispatch_async(self.concurrentQueue, ^{
sleep(self.taskTime);
dispatch_group_leave(group);
});
dispatch_group_enter(group);
dispatch_async(self.concurrentQueue, ^{
sleep(self.taskTime);
dispatch_group_leave(group);
});
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
NSLog(@"所有任务完成,可以更新UI");
});
相应的swift版本为:
let group = DispatchGroup()
group.enter()
DispatchQueue.global().async {
sleep(2)
group.leave()
}
group.enter()
DispatchQueue.global().async {
sleep(2)
group.leave()
}
group.notify(queue: DispatchQueue.main) {
print("所有任务完成,可以更新UI")
}
值类型
- Swift中
String,Array,Dictionary都是值类型, 而OC中NSString,NSArray,NSDictionary都是引用类型. - 但是赋值时并没有产生复制, 而是原对象发生改变时才复制(
Copy-on-Write)- 那你猜猜你访问新对象时访问的是谁? 既然还没有复制. (那此时相当于是一个引用了?)
自动闭包 autoclosure
func printTest1(_ result: () -> Void) {
print("Before")
result()
print("After")
}
printTest1({ print("Hello") })
func printTest2(_ result: @autoclosure () -> Void) {
print("Before")
result()
print("After")
}
printTest2(print("Hello"))
简单来说, @autoclosure就是自动把闭包参数包裹起来, 也就是说, 你可以不用写{}了, 直接写参数即可, 下面有一个例子讲述了怎么灵活利用这个特性(而不是仅仅是简化代码).
模式匹配
swift中switch-case不仅仅是枚举在用, 还有更多的场景:
// 元组
let point = (2, 0)
switch point {
case (let x, 0):
print("on the x-axis with an x value of \(x)")
case (0, let y):
print("on the y-axis with a y value of \(y)")
case let (x, y) where x == y:
print("equal")
case let (x, y):
print("somewhere else at (\(x), \(y))")
}
// 注意, 如果把let (x, y)放到有约束的句子前面, 那么即使(2, 2)也不会输出equal, 也就是说, case重合, 谁先命中算谁的, 等于是一个if-else的语法糖
// 范围
let score = 85
switch score {
case 90...100:
print("Excellent!")
case 80...89:
print("Good")
case 70...79:
print("Average")
case 60...69:
print("Passing")
default:
print("Failing")
}
递归枚举
从例子来看, 能被递归的枚举(indirect)意思是关联数据可以也是这类枚举, 这样就可以用递归枚举实现一棵树了(因为一个node的子节点也是一个node):
// 定义树的递归枚举
indirect enum Tree<T> {
case leaf(T) // 叶子节点,包含一个值
case branch(T, [Tree<T>]) // 分支节点,包含一个值和多个子节点
}
// 创建一棵树
let tree: Tree<String> = .branch("Root", [
.leaf("Leaf1"),
.branch("Branch1", [
.leaf("Leaf2"),
.leaf("Leaf3")
]),
.leaf("Leaf4")
])
// 打印树的结构
func printTree<T>(_ tree: Tree<T>, level: Int = 0) {
switch tree {
case let .leaf(value):
print(String(repeating: " ", count: level) + "Leaf: \(value)")
case let .branch(value, children):
print(String(repeating: " ", count: level) + "Branch: \(value)")
for child in children {
printTree(child, level: level + 1)
}
}
}
printTree(tree)
属性包装器
暂时先看这篇文章
但是可以用这个例子同时复习一下上面的@autoclosure:
@propertyWrapper
struct Lazy<Value> {
private var value: Value?
private let initializer: () -> Value
var wrappedValue: Value {
mutating get {
if let value = value {
return value
} else {
let newValue = initializer()
value = newValue
return newValue
}
}
set {
value = newValue
}
}
// 1. 留意这里, 添加了一个autoclosure
init(wrappedValue initializer: @autoclosure @escaping () -> Value) {
self.initializer = initializer
}
}
struct HeavyObject {
init() {
print("HeavyObject initialized")
}
}
struct Container {
// 2. 这里是为什么要加autoclosure的原因
// 不然的话, 你需要传入闭包: { HeavyObject() } 而不是对象: HeavyObject()
// 也就是说, autoclosure的另一个作用出现了, 能统一代码风格
// 这样你在不需要Lazy的时候, 只需要删掉包装器, 而不需要把初始化器由闭包改成普通的对象
@Lazy
var heavyObject: HeavyObject = HeavyObject()
}
var container = Container()
print("Before accessing heavyObject")
print(container.heavyObject)
- 包装器的核心是对
wrappedValue进行读写, 一般用一个value来保存它的值, 但是你是存到别的结构里比如UserDefaults里, 就不需要了. - 包装器用的是装饰器模式,也就是说,它其实已经是另一个类了,对于本例,是一个
Lazy类
@Lazy var heavyObject: HeavyObject = HeavyObject()这句话本质上是这样:
private var _heavyObject = Lazy<HeavyObject>(wrappedValue: HeavyObject())
var heavyObject: HeavyObject {
get { _heavyObject.wrappedValue }
set { _heavyObject.wrappedValue = newValue }
}
即
- 从书面读写看,语义上是延迟执行
heavyObject的初始化,事实上也做到了 - 实现层面,则是把一个
()->Value闭包作为参数传入Lazy,也就是赋值语句的右半边- 但是由于
@autoclosure语法糖,这个闭包可以省略{},直接传入HeavyObject(),也就是我们现在看到的这样
- 但是由于
- 赋值语句左边有更复杂的内部逻辑,上面看到了,定义的变量类型还是
HeavyObject,但是同时生成了一个_heavyObject的实例变量,类型是Lazy<HeavyObject>,然后改写了heavyObject的getter和setter,使得heavyObject的读写操作都交给了_heavyObject的wrappedValue属性。
要深刻理解这个,可以从加不加@Lazy来比较区别:
- 添加后,这个赋值语句的表现已经和内部实现完全脱节了,但是对用户是无感的,因为封装了对实际的存储对象
Lazy的访问(通过其wrappedValue),与其说heavyObject是一个HeavyObject类型的属性,还不如说它能“得到”这个类型 - 不添加的话,那就是普通的声明时实现的普通赋值了。
projectValue
- 如果你的属性是包装过的, 那么你可以这个类型/结构体里使用属性对应的变量名, 这是常规用法
- 你要使用这个属性内部的方法(因为对外只暴露了
wrappedValue), 你需要加下划线, 比如_x, 它返回的是包装器本身- 但是, 你就不能在这个类外部使用
_x, 因为swift实现为private
- 但是, 你就不能在这个类外部使用
- 使用
projectedValue可以在外部访问到包装器本身, 用法是把上面的下划线改为$, 如$x
@propertyWrapper
struct Wrapper<T> {
var wrappedValue: T
var projectedValue: Wrapper<T> { return self }
func foo() { print("Foo") }
}
struct HasWrapper {
@Wrapper var x = 0
// 内部使用
func method() {
print(x) // `wrappedValue`
print(_x) // wrapper type itself
print($x) // `projectedValue`
}
}
// 外部使用:
let hasWrapper = HasWrapper()
hasWrapper.x.foo() // wrong, 因为.x指向的是wrappedValue, 也就是值本身
hasWrapper.$x.foo() // ok, 返回了包装器对象, 所以能读方法
haswrapper._x.foo() // wrong, 因为它是private的
逃逸闭包
- 逃逸闭包: 闭包的生命周期超过了函数的生命周期(或者说在函数返回之后才会被执行), 比如异步操作, 闭包会持有函数的上下文, 上下文里可能包含一些引用, 如果闭包逃逸了, 那么这些引用的生命周期就会超过函数的生命周期, 导致内存泄漏.
- 非逃逸闭包: 闭包的生命周期不会超过函数的生命周期, 比如函数内部定义的闭包, 闭包的生命周期和函数的生命周期是一样的, 不会持有函数的上下文, 也就不会导致内存泄漏.
var completionHandlers: [() -> Void] = []
func someFunctionWithEscapingClosure(completionHandler: @escaping () -> Void) {
completionHandlers.append(completionHandler)
}
这个例子里, 闭包被添加到一个数组, 而这个数组什么时候用到是不确定的, 所以这个闭包是逃逸的.
- 将一个闭包标记为
@escaping意味着你必须在闭包中显式地引用self。 - 相对的,非逃逸闭包可以隐式引用
self。
func someFunctionWithNonescapingClosure(closure: () -> Void) {
closure()
}
class SomeClass {
var x = 10
func doSomething() {
someFunctionWithEscapingClosure { self.x = 100 }
someFunctionWithNonescapingClosure { x = 200 }
}
}
- 上述两个方法, 第一个只是存了闭包, 第二个是直接调用了闭包
- 写代码的时候怎么知道第一个需要显式引用
self呢? 显然就得靠@escaping来告之了(顺便, 它也能告之编译器, 这个闭包是逃逸的, 所以编译器会检查闭包里有没有显式引用self)
这一节对应
Objective-C的block为什么要copy来理解。但凡非逃逸的,根本不需要考虑需不需要copy,也不需要考虑循环引用,因为block已经被调用了。
所以逃逸闭包就是把block复制到堆上的这个过程。
栈堆数据同步,在OC里是靠__block实现的,在Swift里,虽然也能读取上下文,但是要修改的话,需要把要修改的变量用参数传进去,然后用&或inout标记:
var x = 10
let closure = { [&x] in
x = 20 // 可以修改
}
反射
反射是一种机制,允许程序在运行时查询和操作对象的属性和方法。在Swift中,反射主要通过Mirror类型来实现。使用反射,你可以动态地获取对象的类型信息,遍历对象的属性等,而不需要在编译时知道这些信息。
- 使用
Mirror可以查看任意实例的类型信息,包括类名、属性名及其值。这对于调试、序列化或实现通用代码非常有用。 - 反射的使用包括创建实例的
Mirror,然后通过这个Mirror来访问实例的各种信息。虽然Swift的反射能力不如动态语言(如Python),但它在处理不透明类型或进行类型探索时仍然非常有用。 - 反射在Swift中的使用场景相对有限,因为频繁使用反射可能会导致代码难以理解和维护。通常,它被用在需要大量动态行为的库或框架中,如序列化库或依赖注入框架。
Swift 中的编译时多态性和运行时多态性有何区别?
- 编译时多态性(也称为静态多态性)主要通过方法重载和泛型实现。在编译时,编译器根据调用的参数类型和数量决定使用哪个具体的方法或函数。
- 泛型也是编译时多态性的一个例子,它允许函数或类型与任何数据类型一起工作,类型检查发生在编译时。
- 运行时多态性(也称为动态多态性)在Swift中主要通过继承和协议来实现。它允许在运行时决定调用哪个对象的哪个方法,这依赖于对象的实际类型。在Swift中,类的继承关系和协议的实现提供了运行时多态性,使得同一接口可以有多个实现,具体使用哪个实现在运行时通过动态派发来决定。 编译时多态性提供了更好的性能,因为方法调用的解析在编译时完成;而运行时多态性提供了更高的灵活性,允许更加动态的行为,但可能会略微牺牲性能。
SwiftUI
- 使用属性包装器来监听属性值的变化,常用的包装器有
@State、@Binding、@ObservedObject和@EnvironmentObject
页面关闭后GCD的去向
- 页面关闭后, GCD 的任务会继续执行, 因为 GCD 的任务是在后台线程执行的, 而后台线程的生命周期是和 App 生命周期一致的, 所以 GCD 的任务会继续执行, 直到任务完成或者被取消.
- 所以block里要使用
weak,strong的转换, 一来避免崩溃(当前UI已不存在), 二来确保(if判断之后)这段小作用域内self时还在. - deinit / dealloc 不能保证任务被清理
Struct, Class的区别
几个主要区别为:
- 值类型和引用类型(复制和ARC)
- 不能继承和单继承
- struct 会自动生成一个「成员逐一初始化器(
memberwise initializer)」,要求传入所有未提供默认值的存储属性;而 class 不会自动生成这样的初始化器。- struct: 一旦你手动定义了任何 init,Swift 就不再自动生成 memberwise initializer(除非你用 extension 显式添加)。
- class: 如果任何存储属性没有默认值,而你又没写任何 init → 编译错误!
- Swift 标准库的设计理念:默认使用结构体,除非确实需要引用语义或继承。比如网络请求的 Response 模型用结构体,ViewController 用类,ViewModel 用结构体,
- 值语义,赋值时复制,无引用计数,无继承
- 在 Objective-C 中,我们主要使用的是类(对象),C 语言的结构体作为补充存在。仅在底层、性能关键或与 C 交互的地方使用结构体。比如 iOS 开发中,几乎每天都在用 CGRect、CGPoint 这些结构体,但定义自己的业务模型时,基本都用类。
动态库和静态库的区别
- 静态库是编译期打包进主App二进制文件的, 动态库不会, 只保留符号引用(动态链接+懒加载, 运行时由dyld从Frameworks/目录加载
.framework) - 所以静态库是用到就复制一份, 而动态库虽然无法跨进程跨App共享(无法复制到系统级共享位置),但是同属于一个
App Group的App和小组件,是可以共享的, 相反, 用.a文件共享仍然会各复制一份, 增加打包文件体积 Cocoapods引入的三方库, 标记了use_frameworks!的, 会生成动态库, 否则生成静态库- 静态库不能包含资源
.a文件本质上是多个.o(目标文件)的打包,只包含编译后的机器码和符号;- 不包含任何资源文件(如图片、音频、xib、storyboard、plist、.bundle 等);
- Xcode 在链接
.a时,只处理代码,不处理资源。 - 所以但凡涉及资源, 不要选择静态库, 因为那增加了复杂性, 默认用户自行把正确的资源加载到了主bundle里
Cocoapods机制下:- 在
use_frameworks!模式下 → 资源进入MyLib.framework/Resources/ - 在静态库模式下 → 资源进入主 App 的
MyLibResources.bundle
- 在
Cocoapods下, 三方库编写时, 通过自身bundle访问资源:
NSBundle *bundle = [NSBundle bundleForClass:[MyLibClass class]];
UIImage *image = [UIImage imageNamed:@"icon" inBundle:bundle compatibleWithTraitCollection:nil];
Children
Backlinks